Did you know you can leverage Kafka with an HTTP Sink Connector to connect to the Treasure Data Customer Data Platform to enable customer journeys based on real time customer data? Well, you can, and in this article I'm going to walk you through three ways you can do it.
1. **Confluent Cloud** - Cloud hosted, setup with GUI.
2. **Confluent Platform** - Locally hosted, setup with JSON config file.
3. **Apache Kafka (OSS)** with Aiven's HTTP Sink Connector - Host where you see fit, use separate HTTP Sink connector. This connector has slightly different parameters available, does not support batching.
## What is Kafka?
In case you are not aware, Kafka acts as a real-time data streaming platform, allowing the IT department to efficiently ingest, process, and manage vast amounts of data from various sources. The Treasure Data Customer Data Platform also offers a real-time capability. The combination of Kafka and TD CDP allows marketers to design and execute customer journeys based on real-time customer behavior with an existing central data streaming platform. In addition, the IT team can ensure seamless data integration and synchronization across different systems, applications, and databases. This simplifies the data management process and enables IT to maintain a single source of truth for customer data.
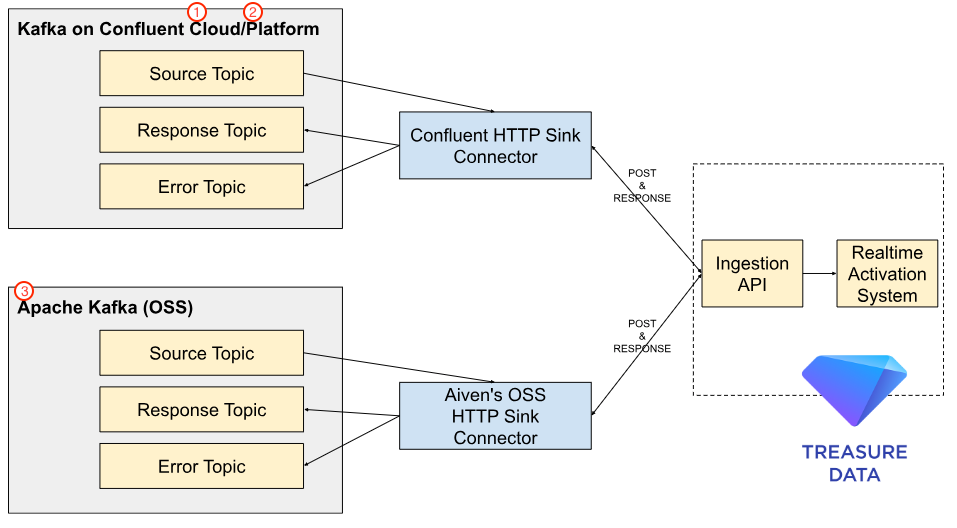
## What are the Kafka options?
Confluent provides two Kafka options: **Confluent Cloud** (managed service) and **Confluent Platform** (on-premise service). These services officially support HTTP Sink Connector to integrate Kafka with an API via HTTPS. This connector is available in a Sink configuration to pull data from Kafka to a downstream REST API.
Another option is to use open source implementation of Apache Kafka without the Confluent wrappers. To do this you will need to use the Apache Kafka software with a third party HTTP Sink connector. We recommend using the Aiven OSS HTTP Sink Connector as we have had a good experience using it.
With any of these connectors, you can push a record to Treasure Data via Ingestion API in near real-time.
### Table of Contents
- [How HTTP Sink Connector and Ingestion API are Integrated](#how-http-sink-connector-and-ingestion-api-are-integrated)
- [Confluent Cloud setup guide](#confluent-cloud-setup-guide)
- [Prerequisites](#prerequisites)
- [Configure the Confluent HTTP Sink Connector via GUI](#configure-the-confluent-http-sink-connector-via-gui)
- [Authentication](#authentication)
- [Configuration](#configuration)
- [Verify Data](#verify-data)
- [Check the Data Availability on Treasure Data](#check-the-data-availability-on-treasure-data)
- [Confluent Platform setup guide](#confluent-platform-setup-guide)
- [Prerequisites](#prerequisites-1)
- [Install Kafka Connect Framework](#install-kafka-connect-framework)
- [Install the HTTP Sink Connector Plugin](#install-the-http-sink-connector-plugin)
- [Configure the HTTP Sink Connector](#configure-the-http-sink-connector)
- [Confluent Platform](#confluent-platform)
- [Apache Kafka setup guide](#apache-kafka-setup-guide)
- [Start the Aiven HTTP Sink Connector](#start-the-aiven-http-sink-connector)
# How HTTP Sink Connector and Ingestion API are Integrated
HTTP Sink connector consumes records from Kafka topic(s) and converts each record value from Avro, JSON, etc., to a JSON with `request.body.format=json` before sending it in the request body to the configured `http.api.url`, which optionally can reference the record key and/or topic name.
The Ingestion API supports a POST request to acquire converted JSON records. The connector batches records up to the set `batch.max.size`before sending the batched request to the API. Each record is converted to its JSON representation with `request.body.format=json` and then separated with the `batch.separator`.
Here are some common parameters for HTTP Sink Connector in the configuration file to send a POST request to Ingestion API. For more information, review [Importing Table Records Using the Data Ingestion API](https://docs.treasuredata.com/products/customer-data-platform/integration-hub/streaming/importing-table-records-using-the-data-ingestion-api).
Records are transformed for Ingestion API by using the following parameters for a **single** JSON request.
```json
http.api.url: https://us01.records.in.treasuredata.com/{database_name}/{table_name}
request.method: POST
http.authorization.type: none
http.headers.content.type: application/vnd.treasuredata.v1.single+json
http.headers.additional: "Authorization: TD1 | "
batch.max.size: 1
request.body.format: json
batch.json.as.array: false
```
In the case of a high message throughput environment, you might want to ingest multiple records in one JSON record per request. In this scenario, you will change the parameter to support ingesting multiple records with the Ingestion API.
```json
http.api.url: https://us01.records.in.treasuredata.com/{database_name}/{table_name}
request.method: POST
http.authorization.type: none
http.headers.content.type: application/vnd.treasuredata.v1+json
http.headers.additional: "Authorization: TD1 | "
batch.max.size: 2 (Up to 500)
request.body.format: json
batch.json.as.array: true
Batch prefix: {"records":
Batch suffix: }
Batch separator: ,
```
The rest of this article will be detailed instructions on how to integrate Kafka with Treasure Data CDP.
# Confluent Cloud setup guide
Confluent Cloud is a managed Kafka service based on Apache Kafka. The HTTP Sink Connector allows you to retrieve data from Kafka topics and send it to Treasure Data as an external HTTP endpoint. This tutorial describes the steps to set up the HTTP Sink Connector with Confluent Cloud.
INFO
The following steps might be different from the most recent Confluent Cloud user interface.
## Prerequisites
- Confluent Cloud Paid Account and Kafka Cluster
- Basic understanding of Confluent Cloud
- Topics in your Kafka cluster have messages
TIP
If you don’t have any production data, test out dummy data to Kafka topics using [the Datagen Source Connector](https://docs.confluent.io/kafka-connectors/datagen/current/overview.html).
## Configure the Confluent HTTP Sink Connector via GUI
1. Navigate to the **Connectors** section.
2. Select **New Connector** to create a new connector.
3. Select **HTTP Sink** from the available connectors.
INFO
You might find two HTTP Sink connectors: HTTP Sink and HTTP Sink Connector. When you use Confluent Cloud, choose **HTTP Sink**.
1. Select **Credentials and Access** permissions based on your requirements.
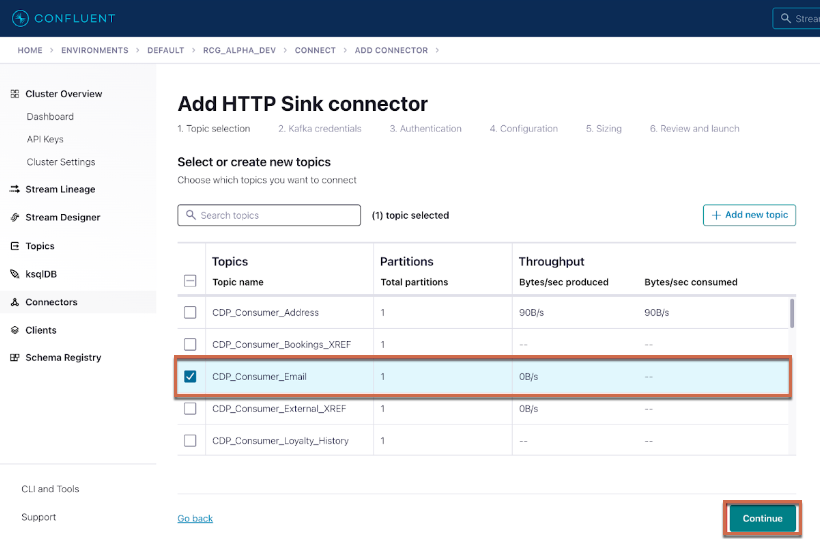
## Authentication
On the connector's Authentication page, provide the required settings:
| Parameter | Description |
| --- | --- |
| HTTP URL | ex. `https://us01.records.in.treasuredata.com/support/kafka_sample` . The format is `https://us01.records.in.treasuredata.com/{database_name}/{table_name}`. For more information, review [Importing Table Records Using the Data Ingestion API](https://docs.treasuredata.com/products/customer-data-platform/integration-hub/streaming/importing-table-records-using-the-data-ingestion-api). |
| SSL Protocol | TLSv1.2 |
| Enable Host verification | false |
| Endpoint Authentication Type | NONE |
INFO
If you use Master APIKEY, you can use Confluent cluster static IP addresses for your user IP Whitelist.
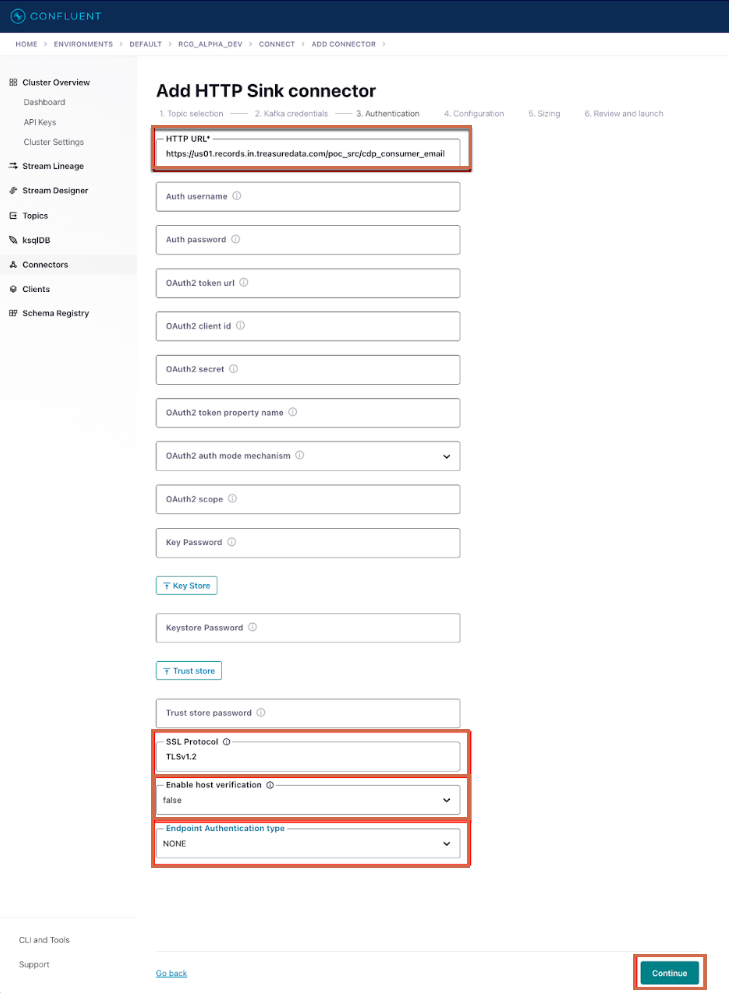
## Configuration
You have the option to select a single record or multiple record format by toggling the **Batch json as array** field. The fields for both Single and Multiple records are listed below. Make sure to select whichever you need and then press **Continue**.
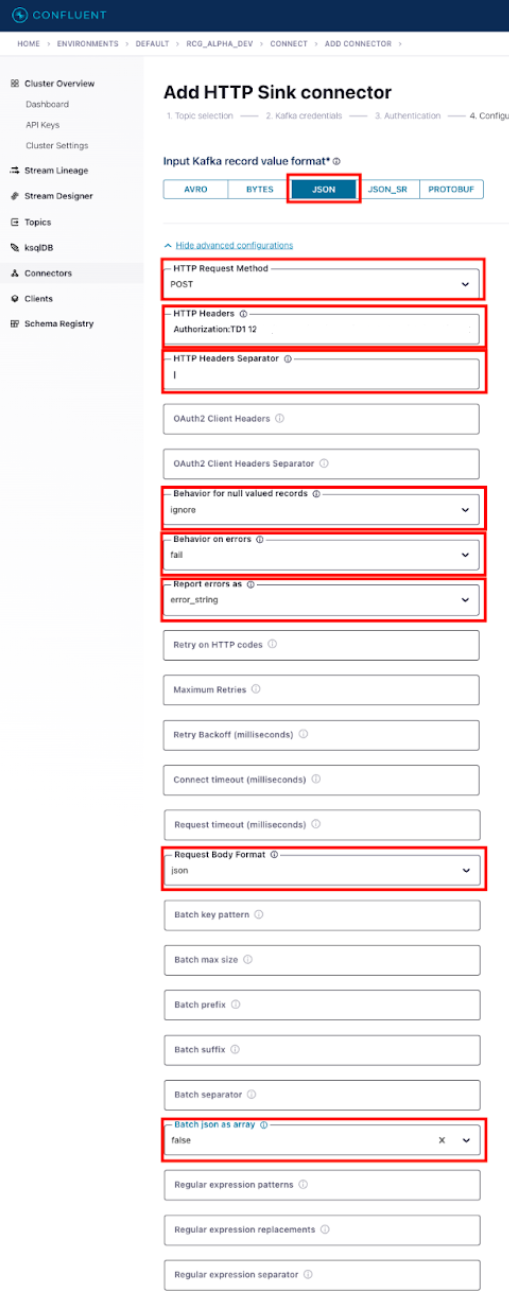
```md Parameters for Single Record
- Input Kafka record value format:
- Choose the appropriate format based on your current topic setting
- HTTP Request Method: POST
- HTTP Headers: Authorization: TD1 XXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1.single+json
- Put the Treasure Data API Key after TD1, note the space between `TD1` and the TD API key.
- HTTP Headers Separator: |
- Behavior for null valued records: ignore
- Behavior on errors: fail
- Based on your requirements
- Report errors as: error_string
- Request Body Format: json
- Batch json as array: false
- Batch max size: 1
```
```md Parameters for Multiple Records
- Input Kafka record value format:
- Choose the appropriate format based on your current topic setting
- HTTP Request Method: POST
- HTTP Headers: Authorization: TD1 XXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1+json
- Put the Treasure Data API Key after TD1, note the space between `TD1` and the TD API key.
- HTTP Headers Separator: |
- Behavior for null valued records: ignore
- Behavior on errors: fail
- Based on your requirements
- Report errors as: error_string
- Request Body Format: json
- Batch json as array: true
- Batch max size: 500
- Batch prefix: {"records":
- Batch suffix: }
```
## Verify Data
After the configuration is complete, the connector starts automatically. On the topic page, review how many records start with `success_`.
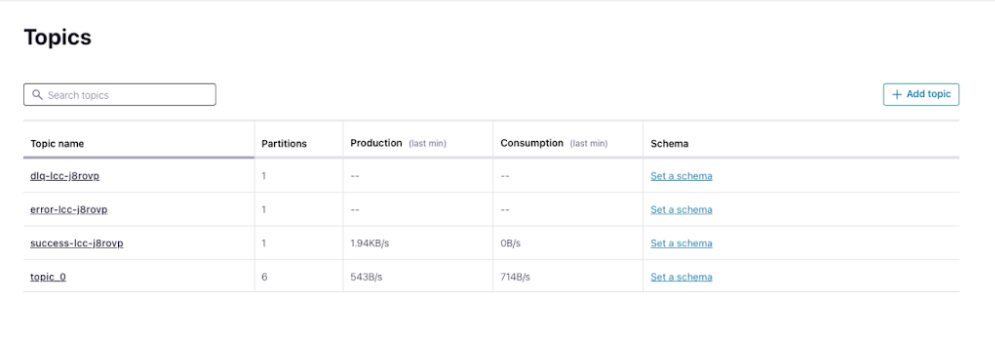
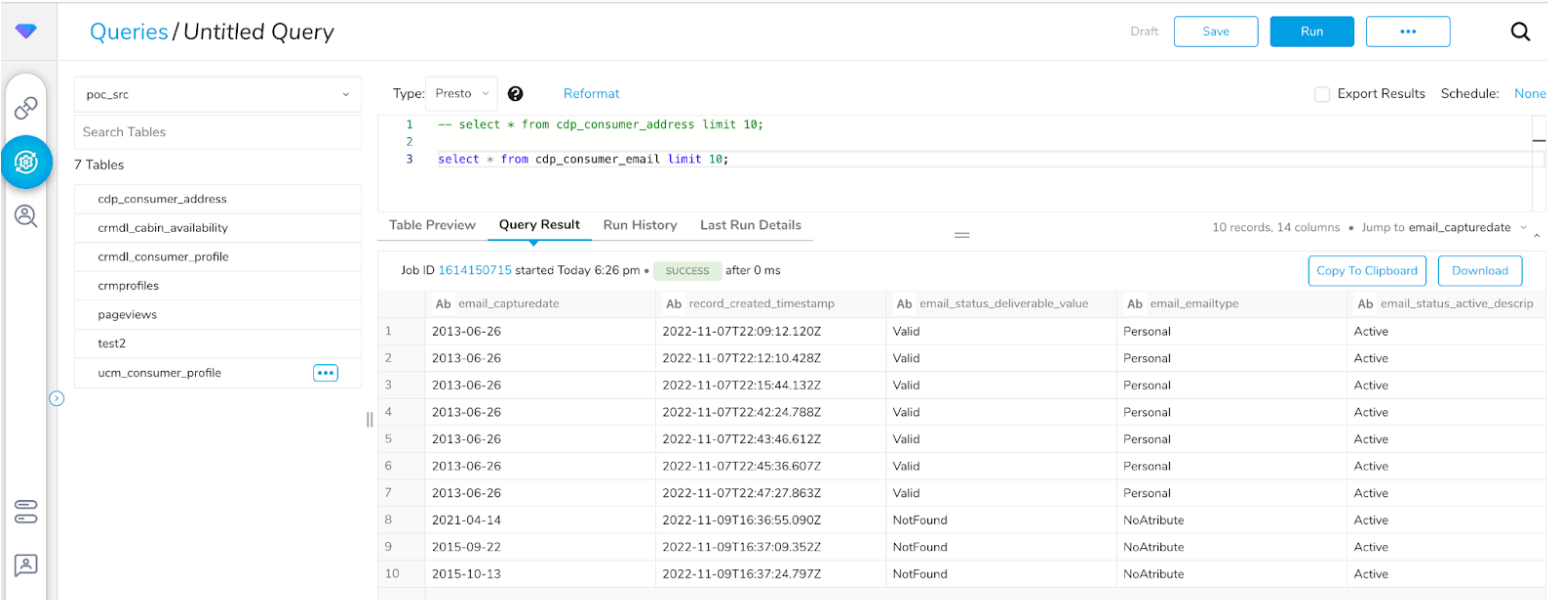
## Check the Data Availability on Treasure Data
# Confluent Platform setup guide
Apache Kafka is an open-source distributed event streaming platform, while Confluent Platform is a commercial distribution of Kafka that extends it with additional features and tools to simplify deployment and management for enterprises. Use the proper platform for your company environment. Both platforms support HTTP Sink Connector, which allows you to retrieve data from Kafka topics and send it to Treasure Data as an external HTTP endpoint. This tutorial describes the steps to set up the HTTP Sink Connector with Confluent Platform and Apache Kafka.
## Prerequisites
- Confluent Platform paid license or Apache Kafka cluster
- Confluent Platform requires [HTTP Sink Connector](https://docs.confluent.io/kafka-connectors/http/current/overview.html) supported by Confluent.
- Apache Kafka requires [Aiven's HTTP Sink Connector](https://github.com/Aiven-Open/http-connector-for-apache-kafka)maintained by Kafka community.
INFO
Treasure Data doesn’t provide commercial support for these connectors.
- Basic understanding of Apache Kafka
## Install Kafka Connect Framework
Ensure you have Kafka Connect installed, which is a framework for connecting external systems to Kafka. If you are using the Confluent Platform, Kafka Connect comes pre-installed. Otherwise, you need to download and install it separately.
- [Apache Kafka Connect](https://kafka.apache.org/documentation/#connect)
- [Confluent Kafka Connect](https://docs.confluent.io/platform/current/connect/index.html)
## Install the HTTP Sink Connector Plugin
To send data to an HTTP endpoint, you'll need an HTTP Sink Connector plugin. Check the Confluent Hub or other sources for the specific plugin version compatible with your Kafka Connect version. Then, place the downloaded HTTP Sink Connector plugin (JAR file) into the appropriate Kafka Connect plugin directory.
- [Download via Confluent Hub for Confluent Platform](https://docs.confluent.io/kafka-connectors/http/current/overview.html)
- [Download via Github for Apache Kafka](https://github.com/Aiven-Open/http-connector-for-apache-kafka)
## Configure the HTTP Sink Connector
Create a configuration file (JSON or properties) to define the HTTP Sink Connector's settings. This configuration file typically includes the following properties:
| Parameter | Description |
| --- | --- |
| `name` | A unique name for the connector. |
| `connector.class` | The class name for the HTTP Sink Connector (e.g., `io.confluent.connect.http.HttpSinkConnector`). |
| `tasks.max` | The number of tasks to be created for the connector (usually equal to the number of Kafka partitions). |
| `topics` | The Kafka topics from which data will be consumed and sent to the HTTP endpoint. |
| `http.api.url` | The URL of the HTTP endpoint to which the data will be sent. |
| `http.api.method` | The HTTP method to use when making the request (e.g., `POST`, `PUT`, etc.). |
| `http.headers` | Additional HTTP headers to include in the request. |
| `http.timeout.ms` | The timeout for the HTTP request. |
Other optional properties as per your use case and requirements.
These configuration properties might vary depending on the specific version of Kafka Connect and the HTTP Sink Connector plugin you are using. Always refer to the official documentation and the plugin's documentation for the most up-to-date information and instructions.
- [Confluent Platform](https://docs.confluent.io/kafka-connectors/http/current/connector_config.html)
- [Apache Kafka](https://github.com/Aiven-Open/http-connector-for-apache-kafka/blob/main/docs/sink-connector-config-options.rst)
### Confluent Platform
Create a configuration JSON file to define the HTTP Sink Connector's settings. Follow the guidelines for the connector in Kafka's [Sink Connector Configuration Properties](https://docs.confluent.io/kafka-connectors/http/current/connector_config.html#http-sink-connector-configuration-properties).
```json Single-row Ingestion JSON Example
{
"name": "tdsinglejsonHttpSink",
"config":
{
"topics": "rest-messages5",
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"http.api.url": "https://us01.records.in.treasuredata.com/{database_name}/{table_name}",
"request.method": "POST",
"headers": "Authorization:TD1 XXXXX/xxxxx|Content-Type:application/vnd.treasuredata.v1.single+json",
"header.separator": "|",
"report.errors.as": "error_string",
"request.body.format": "json",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batch.prefix":"",
"batch.suffix":"",
"batch.max.size": "1",
"batch.json.as.array": "false",
"tasks.max": "1",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.name": "success-responses",
"reporter.result.topic.replication.factor": "1",
"reporter.error.topic.name": "error-responses",
"reporter.error.topic.replication.factor": "1",
"ssl.enabled":"true",
"https.ssl.protocol":"TLSv1.2"
}
}
```
```json Multi-row Ingestion JSON Example
{
"name": "tdBatchHttpSink",
"config":
{
"topics": "rest-messages5",
"connector.class": "io.confluent.connect.http.HttpSinkConnector",
"http.api.url": "https://us01.records.in.treasuredata.com/{database_name}/{table_name},
"request.method": "POST",
"headers": "Authorization:TD1 XXXX/xxxx|Content-Type:application/vnd.treasuredata.v1+json",
"header.separator": "|",
"report.errors.as": "error_string",
"request.body.format": "string",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batch.prefix":"{\"records\":",
"batch.suffix":"}",
"batch.max.size": "500",
"batch.json.as.array": "true",
"tasks.max": "1",
"confluent.topic.bootstrap.servers": "localhost:9092",
"confluent.topic.replication.factor": "1",
"reporter.bootstrap.servers": "localhost:9092",
"reporter.result.topic.name": "success-responses",
"reporter.result.topic.replication.factor": "1",
"reporter.error.topic.name": "error-responses",
"reporter.error.topic.replication.factor": "1",
"ssl.enabled":"true",
"https.ssl.protocol":"TLSv1.2"
}
}
```
# Apache Kafka setup guide
Lets walk through how to setup Apache Kafka with Treasure Data. Start by creating a configuration JSON file to define the HTTP Sink Connector's settings. Follow the guidelines for the connector in Kafka's [Sink Connector Configuration by Aiven](https://github.com/Aiven-Open/http-connector-for-apache-kafka/blob/main/docs/sink-connector-config-options.rst). They support similar parameters that Confluent HTTP Sink Connector supported.
```json
{
"name": "tdCommunityHttpSink",
"config":
{
"topics.regex": "td-rest-messages1",
"connector.class": "io.aiven.kafka.connect.http.HttpSinkConnector",
"http.url": "https://us01.records.in.treasuredata.com/{database_name}/{table_name}",
"http.authorization.type": "none",
"http.headers.content.type": "application/vnd.treasuredata.v1.single+json",
"http.headers.additional": "Authorization: TD1 XXXX/xxxx",
"key.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": "false",
"value.converter.schemas.enable": "false",
"batching.enabled": "false",
"batch.max.size": "1",
"batch.prefix":"{\"records\":[",
"batch.suffix":"]}",
"batch.separator": "n",
"tasks.max": "1"
}
}
```
## Start the Aiven HTTP Sink Connector
Submit the configuration to Kafka Connect to start the HTTP Sink Connector. You can use the confluent command-line tool or make a REST API call to the Kafka Connect REST interface. For detailed information, refer to [KAFKA CONNECT 101](https://developer.confluent.io/courses/kafka-connect/rest-api/). |