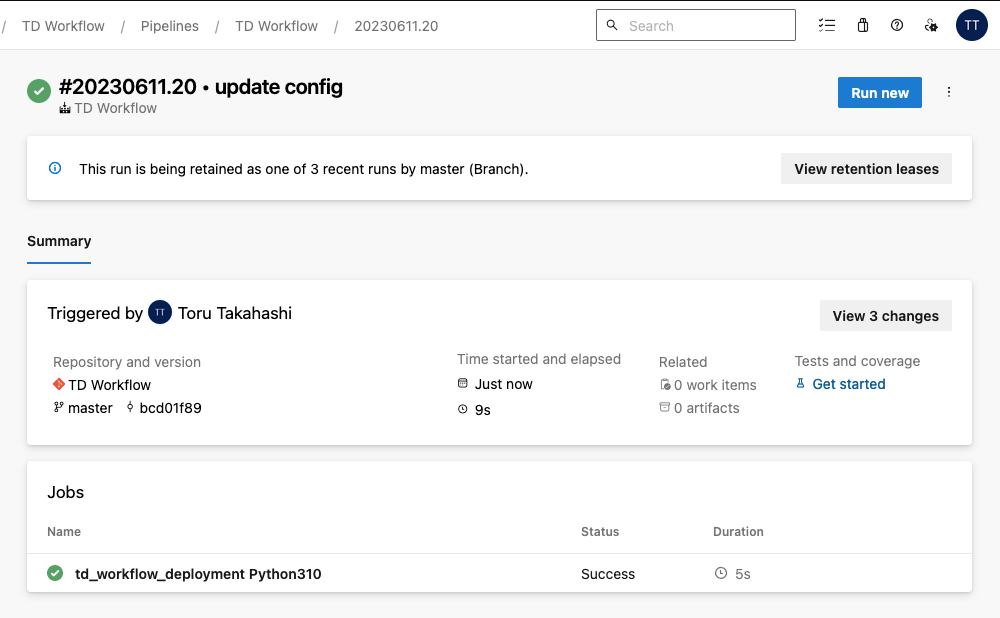
Treasure Workflow can be used with version control tools like Git and CI/CD. However, a recent enablement now allows you to set up a continuous deployment pipeline using Azure Repos and Azure Pipelines in Azure DevOps Sevices.
- Azure Repos
- Azure Pipelines
- Treasure Data User Account
If you have not already done so, create a git repository on Azure Repo for your workflow project. For more information on how to use Azure Repos, see the Azure Repos documentation.
I recommend having the following directory structure in your Treasure Workflow repo.
my_project
├── README.md
├── config
│ ├── params.test.yml <- Configuration file for run through test. Mirrors params.yml except for `td.database`
│ └── params.yml <- Configuration file for production
├── awesome_workflow.dig <- Main workflow to be executed
├── ingest.dig <- Data ingestion workflow
├── py_scripts <- Python scripts directory
│ ├── __init__.py
│ ├── data.py <- Script to upload data to Treasure Data
│ └── my_script.py <- Main script to execute e.g. Data enrichment, ML training
├── queries <- SQL directory
│ └── example.sql
├── run_test.sh <- Test shell script for local run through test
└── test.dig <- Test workflow for local run through test
└── azure-pipeline.yml <- Deploy this repo to Treasure Workflow through Azure Pipeline (This file is automatically created when a new pipeline is created)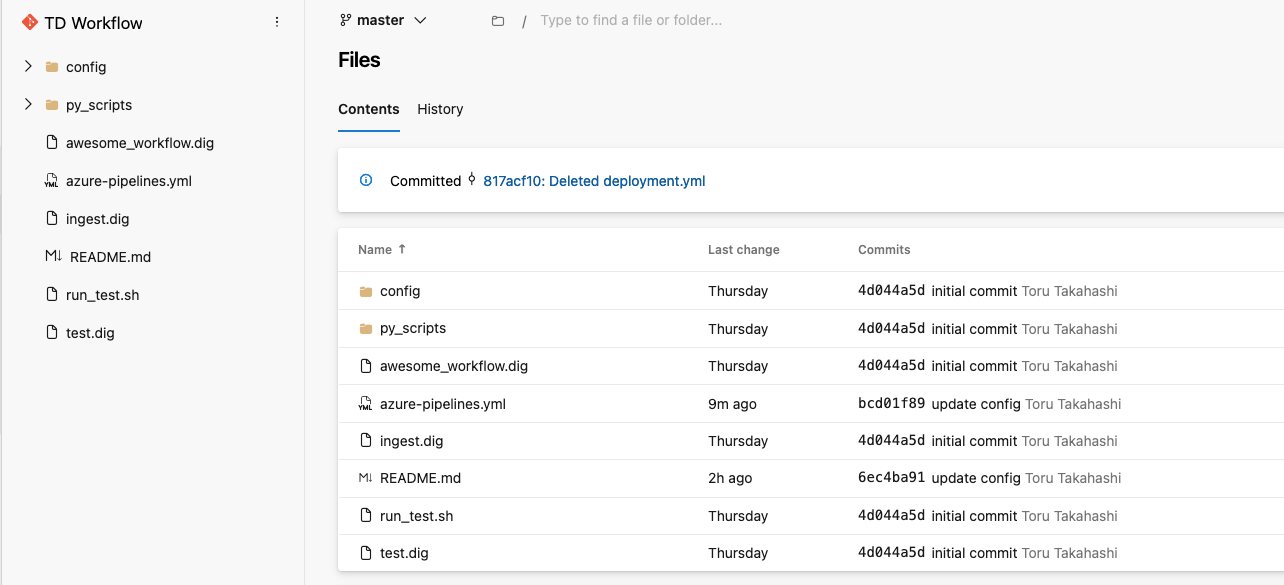
For more information on custom script development, see the blog post "py> operator development guide for Python users."
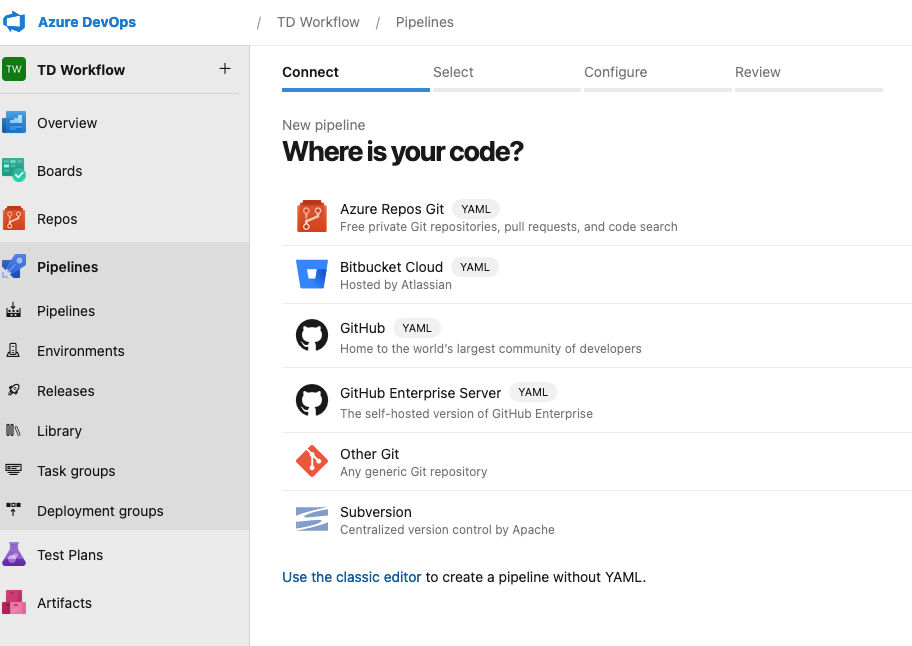
To createa new Azure Pipeline for your project:
- Select Azure Repos Git in Select section
- Select Python Package in Configure section
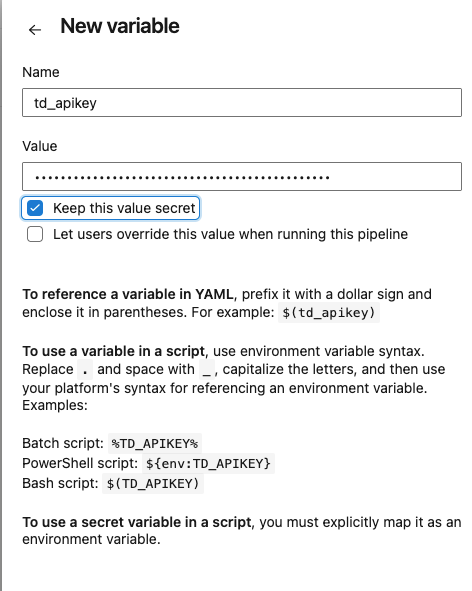
- Set Variables on the right-hand side.
- Enter td_apikey into the Name field
- Enter your TD API key in the Value field.
- Select Keep this value secret.
- Select Save variables.
- Update the Azure Pipeline configuration file for the project. You must update
tdWorkflowEndpointfor your account region andtdPrjNamefor your workflow project in variables
jobs:
- job: 'td_workflow_deployment'
pool:
vmImage: 'ubuntu-latest'
strategy:
matrix:
Python311:
python.version: '3.11'
variables:
tdWorkflowEndpoint: api-workflow.treasuredata.com
# US: api-workflow.treasuredata.com
# EU01: api-workflow.eu01.treasuredata.com
# Tokyo: api-workflow.treasuredata.co.jp
# AP02: api-workflow.ap02.treasuredata.com
# Ref. /en/overview/aboutendpoints
tdPrjName: azure_devops_wf # YOUR PROJECT NAME
steps:
- script: pip install tdworkflow mypy_extensions
displayName: 'Install tdworkflow lib'
- task: PythonScript@0
inputs:
scriptSource: inline
script: |
import os
import sys
import shutil
import tdworkflow
endpoint = "$(tdWorkflowEndpoint)"
apikey = "$(td_apikey)"
project_name = "$(tdPrjName)"
shutil.rmtree('.git/') # Remove unnessary temp files
client = tdworkflow.client.Client(endpoint=endpoint, apikey=apikey)
project = client.create_project(project_name, ".")For more information on Azure Pipeline configuration, see "Azure Pipelines: Create and target an environment."
For workflows to be pushed to Treasure Data, you must configure a TD Master API Key for the project. See Getting Your API Keys for more information.
Azure Pipelines pushes your workflow to Treasure Data and does this every time you push a change to Azure Repos. You can change a deployment condition depending on your needs. Once deployment is completed, Treasure Workflow on Treasure Data is updated automatically.