Treasure Data CDP is now powered by Apache Hive 4! We run more than 100k queries on Hive every day. Due to the extensive usage, we frequently encounter edge cases. Notably, the recent migration from Hive 2 to Hive 4 was a significant undertaking, involving numerous changes. This article explains how we completed the challenging upgrade by leveraging Query ReExecution provided by Apache Hive.
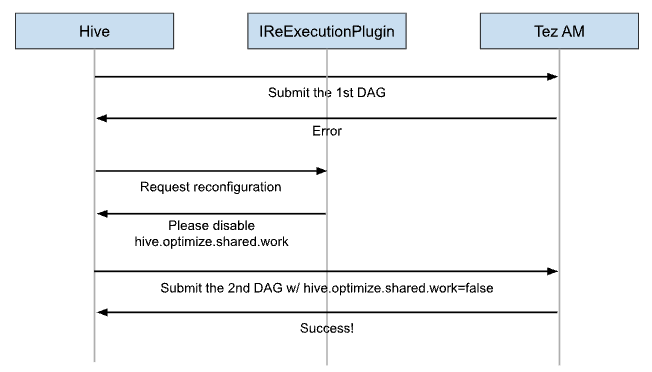
Query ReExecution is a unique feature that enhances the end-to-end reliability of Hive queries. The mechanism is simple. When a compile or runtime error happens, Hive’s driver shares the error context with IReExecutionPlugins, and each IReExecutionPlugin tries to reconfigure Hive’s parameters or operator trees. Therefore, the driver can retry it with different and more promising configurations. You can read more generic information in the official document: Apache Hive : Query ReExecution.
Apache Hive provides several built-in plugins that address common troubles. This section describes some of them, which effectively convey the concept of the re-execution framework.
The first example is ReCompileWithoutCBOPlugin. The name directly indicates its purpose. When Hive fails to compile an SQL query with CBO(Cost-Based Optimizer), it attempts to recompile it without CBO. As of Hive 4.0, there are some known situations where CBO doesn’t work properly, and the planner throws a ReCompileException. ReCompileWithoutCBOPlugin can catch the exception and set hive.cbo.enable = false.
By the way, I have some good news to share. The Hive community has successfully resolved all known CBO issues! ReCompileWithoutCBOPlugin will be less important in the near future.
ReExecutionOverlayPlugin is a more generic re-execution plugin. It is triggered whenever a generic runtime error happens, and it rewrites pre-defined properties. For example, let’s say a Hive user specifies reexec.overlay.xyz = true in their hive-site.xml. In that case, the plugin overwrites xyz in the event of a runtime error.
We configure reexec.overlay.hive.auto.convert.join = false for this plugin. The automatic Map Join conversion is one of the most significant optimizations of Hive. However, with the optimization, edge-case queries can fail due to an out-of-memory error. The plugin enables us to safely turn on such a risky but effective optimization.
We found Query ReExecution would be very promising during our migration from Hive 2.3.2 to Hive 4.0.0. It is not so trivial to migrate more than 100,000 queries to the new version, as you can imagine. Any minor issues affecting 0.01% of queries can have a significant impact on customers' businesses. As Apache Hive is a well-tested software with more than 100,000 unit and integration tests, an unsolved bug is typically tough to resolve. However, it also doesn’t make sense to completely disable great optimizations only for 0.01% of queries. It is also painful to ask customers to apply a workaround configuration every time.
In the face of a handful of bug reports, we devised a very solid solution. If we can implement our own custom IReExecutionPlugins, the small number of errors can be automatically recovered while retaining the default and best configurations for 99.99% of queries. Our open-source DNA prompted us to file a ticket: “HIVE-28555: Adding custom plugins to ReExecution” - a new JIRA ticket to make Query ReExecution extensible. It was merged in a timely manner thanks to Denys Kuzmenko, and we backported it and implemented some custom plugins.
In this section, we will introduce some of our custom plugins that provide workarounds for specific problems.
The recent Hive introduces a powerful optimization called SharedWorkOptimizer. It will extract a shared expression in an Operator tree and merge them effectively. For example, most query engines generate two table scan operators for the following SQL. Apache Hive can generate only one table scan operator.
SELECT *
FROM (SELECT sum(i_current_price) FROM item WHERE i_rec_start_date >= '2000-01-01') a
CROSS JOIN (SELECT sum(i_wholesale_cost) FROM item WHERE i_rec_end_date IS NOT NULL) b;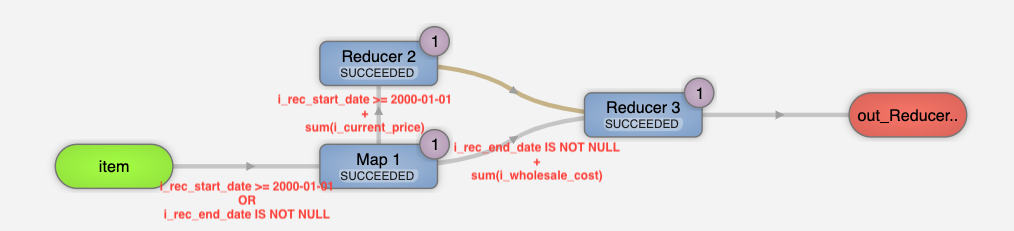
SharedWorkOptimizer can effectively reduce expensive operations. However, as of 4.0, the number of merges is unlimited. We observed that an out-of-memory error happened when a query merged approximately 100 GROUP BY operators into a single execution unit. We reported the issues.
- HIVE-28548: Subdivide memory size allocated to parallel operators
- HIVE-28549: Limit the maximum number of operators merged by SharedWorkOptimizer
As they modified a very fundamental part of Hive, we couldn’t easily conclude how to fix them. However, we were unable to stall the Hive 4 migration and didn’t want to disable the optimization. We wrote a plugin that traverses Hive’s operator trees, detects potentially memory-intensive merges, and retries them with the shared work optimization disabled.
In our environment, many queries randomly hit “HIVE-23010: IllegalStateException in tez.ReduceRecordProcessor when containers are being reused”. As it is non-deterministic, we have not fully unveiled the root cause. However, we identified it would be less likely to happen when we disabled hive.auto.convert.sortmerge.join.reduce.side.
We implemented a plugin to disable the optimization when we found the striking error message.
Throwable exception = hookContext.getException();
LOG.info("exception: " + exception);
if (exception != null && exception instanceof TezRuntimeException) {
LOG.info("exception.getMessage(): " + exception.getMessage());
if (exception.getMessage() != null
&& exception.getMessage().contains("Was expecting dummy store operator but found")) {
LOG.info("Enable the retry flag because the failed"
+ " when containers are being reused or sort merge join");
retryPossible = true;
}
}Our strategy, leveraging the re-execution framework, is very successful. We processed 3,327,264 Hive queries in May 2025, and Query ReExecution recovered a significant number of queries, as shown in the following table.
| Plugin Name | Number of recoveries |
|---|---|
| ReCompileWithoutCBOPlugin | 70,579 |
| ReExecutionOverlayPlugin | 1,812 |
| ReExecutionParallelHashAggPlugin | 21 |
| ReExecutionWasExpectingDummyErrorPlugin | 719 |
We explained the concept of Query ReExecution in Apache Hive, how we extended its functionality, and how we applied it in practical use.
Apache Hive is designed to build a data platform with massive scalability and enterprise-grade reliability. The competence highly empowers Treasure Data CDP and our customers!