In the previous blog post, Orchestrate dbt with Treasure Workflow, we introduced the fundamental concept and basic setup of integrating dbt Core in Treasure Data platform. In this post, we, as the Data Team in Treasure Data, would like to share additional practices that assist us in our daily developments, operations, and communications with our data customers.
In this post, we will include below topics.
- Supporting various dbt CLI commands, and parameters:
- Particularly, the node selection capability allows us to efficiently develop, test, and recover from failures by executing only specific models.
- Creating a batch materialization type for hopping windows refresh:
- This is essential for handling unbounded sources, which are required by the majority of our data models.
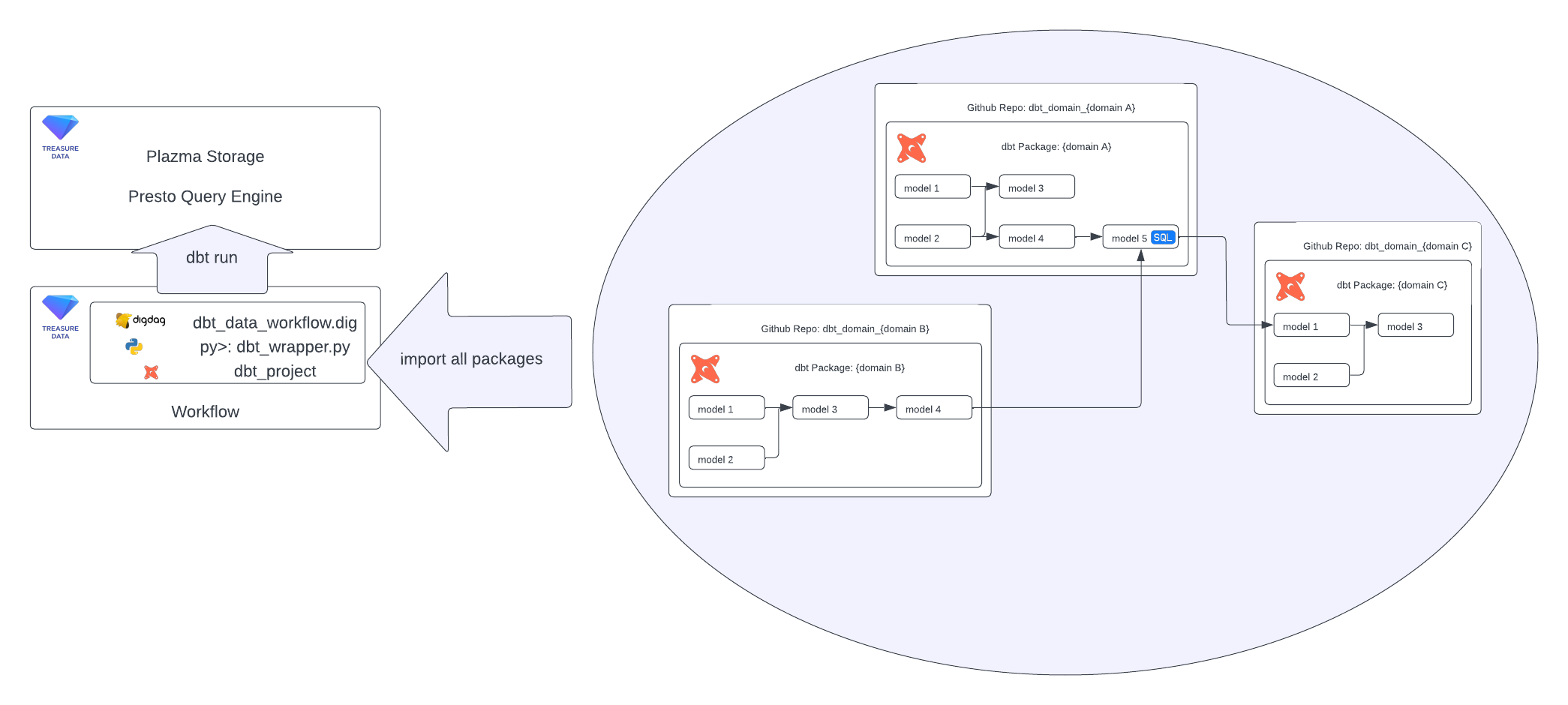
- Adapting the paradigm shift from data monolith to data mesh:
- We utilize dbt packages management to encapsulate data domain implementations, facilitating this shift.
- Providing data customers and developers visibility:
- The documentation generated by dbt allows us to search, traverse the lineage, see the definition of models and columns, and even the actual logic with SQL codes.
In previous blog post, dbt run command invocation is depicted. Besides run command, there are many other useful commands available. docs, deps, and test commands will be demonstrated later, also if you have static CSV asset, the seed command is necessary.
In order to invoke various commands, the command list can be parameterized but also preserved run as the default command.
Parameterize
dbt_command_listintd_wf_project/scripts/dbt_wrapper.py.import os import sys os.system(f"{sys.executable} -m pip install dbt-core==1.6.6 dbt-trino==1.6.2") from dbt.cli.main import dbtRunner DEFAULT_COMMANDS = ','.join([ 'run', ]) def invoke(dbt_commands=DEFAULT_COMMANDS): for cmd in dbt_commands.split(','): dbtRunner().invoke([ *(cmd.split()), '--project-dir', './dbt_project', '--profiles-dir', './dbt_profiles', ])Modify
td_wf_project/dbt_exec_workflow.dig.+dbt_invoke: py>: scripts.dbt_wrapper.invoke _env: TD_API_KEY: ${secret:td.apikey} docker: image: "digdag/digdag-python:3.10"Invoke multiple dbt commands.
$ digdag run dbt_exec_workflow.dig \ --param dbt_commands='test,docs generate' ... # Running dbt test 22:38:25 Running with dbt=1.6.6 22:38:25 Registered adapter: trino=1.6.2 22:38:25 Found 2 models, 2 tests, 1 source, 0 exposures, 0 metrics, 373 macros, 0 groups, 0 semantic models 22:38:25 22:38:27 Concurrency: 2 threads (target='td') 22:38:27 22:38:27 1 of 2 START test not_null_my_first_dbt_model_id ............................... [RUN] 22:38:27 2 of 2 START test not_null_my_second_dbt_model_id .............................. [RUN] 22:38:29 1 of 2 PASS not_null_my_first_dbt_model_id ..................................... [PASS in 1.46s] 22:38:29 2 of 2 PASS not_null_my_second_dbt_model_id .................................... [PASS in 1.55s] 22:38:29 22:38:29 Finished running 2 tests in 0 hours 0 minutes and 3.36 seconds (3.36s). 22:38:29 22:38:29 Completed successfully 22:38:29 22:38:29 Done. PASS=2 WARN=0 ERROR=0 SKIP=0 TOTAL=2 # Running dbt docs generate 22:38:30 Running with dbt=1.6.6 22:38:30 Registered adapter: trino=1.6.2 22:38:30 Found 2 models, 2 tests, 1 source, 0 exposures, 0 metrics, 373 macros, 0 groups, 0 semantic models 22:38:30 22:38:31 Concurrency: 2 threads (target='td') 22:38:31 22:38:31 Building catalog 22:38:33 Catalog written to .../dbt_in_td_example/td_wf_project/dbt_project/target/catalog.json Success. Task state is saved at .../dbt_in_td_example/td_wf_project/.digdag/status/20231016T000000+0000 directory. * Use --session <daily | hourly | "yyyy-MM-dd[ HH:mm:ss]"> to not reuse the last session time. * Use --rerun, --start +NAME, or --goal +NAME argument to rerun skipped tasks.
Additionally, dbt commands provides many parameter options for configuring the execution behaviors. Among the options, node selection is particular useful for our practices.
When triggering a dbt run execution, all models will be executed by default. However, in some cases, it is preferable to execute only a subset of models, especially as the number of models grows to dozens or even hundreds. For examples,
- When developing a new model in a local environment, it is useful to execute only the specific new model.
- When backfilling a model for a wide time range, executing only the specific backfilling model and all its downstream models is beneficial.
- When performing a full refresh of a report, rerunning all the upstream models of the report ensures freshness.
By adding the parameters handling in td_wf_project/scripts/dbt_wrapper.py, all the Digdag runtime parameters with dbt_ prefix will be passed to dbt invocation.
import os
import sys
os.system(f"{sys.executable} -m pip install dbt-core==1.6.6 dbt-trino==1.6.2")
from dbt.cli.main import dbtRunner
DEFAULT_COMMANDS = ','.join([
'run',
])
def invoke(dbt_commands=DEFAULT_COMMANDS, **kwargs):
for cmd in dbt_commands.split(','):
dbtRunner().invoke([
*(cmd.split()),
'--project-dir', './dbt_project',
'--profiles-dir', './dbt_profiles',
],
**{
k.removeprefix('dbt_'): eval(v)
for k, v in kwargs.items()
if k.startswith('dbt_')
})Then passing parameters from Digdag CLI to dbt is straightforward. For example, by specifying dbt_select='["my_second_dbt_model"]' and dbt_log_format='"debug"', the dbt execution is altered to run only the selected model and to enable debug logging, which writes to stdout.
$ digdag run dbt_exec_workflow.dig --rerun \
--param dbt_select='["my_second_dbt_model"]' \
--param dbt_log_format='"debug"'
...
============================== 18:30:57.343255 | 3dc6e153-5ba8-4a38-a196-240c86e09a7a ==============================
18:30:57.343255 [info ] [MainThread]: Running with dbt=1.6.6
18:30:57.468087 [info ] [MainThread]: Registered adapter: trino=1.6.2
18:30:57.534876 [info ] [MainThread]: Found 2 models, 4 tests, 1 source, 0 exposures, 0 metrics, 373 macros, 0 groups, 0 semantic models
18:30:57.536838 [info ] [MainThread]:
18:31:01.280085 [info ] [MainThread]: Concurrency: 2 threads (target='td')
18:31:01.281881 [info ] [MainThread]:
18:31:01.295982 [info ] [Thread-1 (]: 1 of 1 START sql table model dbt_example_db.my_second_dbt_model ................ [RUN]
18:31:05.746610 [info ] [Thread-1 (]: 1 of 1 OK created sql table model dbt_example_db.my_second_dbt_model ........... [SUCCESS in 4.45s]
18:31:05.753178 [info ] [MainThread]:
18:31:05.753822 [info ] [MainThread]: Finished running 1 table model in 0 hours 0 minutes and 8.22 seconds (8.22s).
18:31:05.764799 [info ] [MainThread]:
18:31:05.765716 [info ] [MainThread]: Completed successfully
18:31:05.766362 [info ] [MainThread]:
18:31:05.767018 [info ] [MainThread]: Done. PASS=1 WARN=0 ERROR=0 SKIP=0 TOTAL=1
Success. Task state is saved at .../dbt_in_td_example/td_wf_project/.digdag/status/20231016T000000+0000 directory.
* Use --session <daily | hourly | "yyyy-MM-dd[ HH:mm:ss]"> to not reuse the last session time.
* Use --rerun, --start +NAME, or --goal +NAME argument to rerun skipped tasks.Or to Combine commands and selection parameters to test & run the specified model.
$ digdag run dbt\_exec\_workflow.dig \
--param dbt\_commands=test,run \
--param dbt\_select='["my\_first\_dbt\_model"]'
...When processing unbounded source data, e.g. event logs, it is impractical to full refresh the dependent models in every run. Although dbt provides the incremental models for partially refresh, however, the incremental models requires:
- either strictly increment in record timestamp column (https://docs.getdbt.com/docs/build/incremental-models#filtering-rows-on-an-incremental-run)
- or have a set of unique key columns (https://docs.getdbt.com/docs/build/incremental-models#defining-a-unique-key-optional)
however in many of our cases, the data sources just don’t have these properties.
Hopping windows refresh is a simple strategy to tackle the “loosely” increment unbounded sources, which remains idempotency at the same time. To implement the hopping windows refresh, it requires:
- time range based refresh - with specifying window size
- periodically triggering - with specifying step size

By creating a customized batch materialization in dbt macro, the refresh time range can be applied to time range delete+insert strategy (without specifying unique key).
- Add batch materialization
td_wf_project/dbt_project/macros/materializations/batch.sql
{% macro get_batch_refresh_sql(target, source, dest_columns, refresh_time_range, full_refresh) -%}
{%- set dest_cols_csv = get_quoted_csv(dest_columns | map(attribute="name")) -%}
{% if full_refresh %}
delete from {{ target }}
where true ;
{% elif refresh_time_range %}
delete from {{ target }}
where {{ refresh_time_range }} ;
{% endif %}
insert into {{ target }} ({{ dest_cols_csv }})
(
select {{ dest_cols_csv }}
from {{ source }}
)
{%- endmacro %}
{% materialization batch, adapter='trino' -%}
{#-- Set vars --#}
{%- set full_refresh = (should_full_refresh()) -%}
{%- set refresh_time_range = config.get('refresh_time_range') -%}
{% set target_relation = this.incorporate(type='table') %}
{% set existing_relation = load_relation(this) %}
{% set tmp_relation = make_temp_relation(this).incorporate(type='table') %}
{% set on_schema_change = incremental_validate_on_schema_change(config.get('on_schema_change'), default='ignore') %}
{{ run_hooks(pre_hooks) }}
{% if existing_relation is none %}
{%- call statement('main') -%}
{{ create_table_as(False, target_relation, sql) }}
{%- endcall -%}
{% else %}
{%- call statement('create_tmp_relation') -%}
{{ create_table_as(True, tmp_relation, sql) }}
{%- endcall -%}
{% do adapter.expand_target_column_types(
from_relation=tmp_relation,
to_relation=target_relation) %}
{#-- Process schema changes. Returns dict of changes if successful. Use source columns for upserting/merging --#}
{% set dest_columns = process_schema_changes(on_schema_change, tmp_relation, existing_relation) %}
{% if not dest_columns %}
{% set dest_columns = adapter.get_columns_in_relation(existing_relation) %}
{% endif %}
{%- call statement('main') -%}
{{ get_batch_refresh_sql(target_relation, tmp_relation, dest_columns, refresh_time_range, full_refresh) }}
{%- endcall -%}
{% endif %}
{% do drop_relation_if_exists(tmp_relation) %}
{{ run_hooks(post_hooks) }}
--{% do persist_docs(target_relation, model) %}
{{ return({'relations': [target_relation]}) }}
{%- endmaterialization %}- Then a batch model can be implemented as below with the specified window size, ex. 2 hours.
{%- set refresh_time_range = "TD_INTERVAL(time, '-2h')" -%}
{{ config(
materialized='batch',
refresh_time_range=refresh_time_range,
) }}
select *
from {{ source('dbt_dev_aws', 'dbt_results') }}
{% if not should_full_refresh() %}
where {{ refresh_time_range }}
{% endif %}- We recommend using Treasure Data’s time range functions as the
refresh_time_rangepredicate, because it can ensure to utilize time-based partitioning and prevent full table scan.
Periodically triggering the workflow can be done by following Register and Schedule the Workflow example.
- Add schedule in
td_wf_project/dbt_exec_workflow.digwith specifying step size (ex. 1 hour) and offset (ex. 15 minutes)
...
timezone: UTC
schedule:
hourly>: 15:00
...In case of a batch model needs to be full refreshed when initialization of backfilling, the full refresh option can be specified through parameters passing.
$ digdag run dbt_exec_workflow.dig --rerun \
--param dbt_select='["my_batch_model"]' \
--param dbt_full_refresh=TrueAs mentioned previously in the introduction. We utilize the dbt packages management as the encapsulation of the data domain implementation. Generally speaking, If your dbt data model consists of multiple business domain, its implementation might be complicated while the modes evolve. One idea to avoid this situation is to separate each domain into independent dbt package.
dbt allows you to configure dependencies on external package by configuring dependencies.yml or packages.yml to your dbt project. This should be at the same level as your dbt_project.yml file.
$ tree .
└── dbt_project
├── dbt_project.yml
└── packages.ymlpackages:
- package: dbt-labs/dbt_utils
version: 1.1.1
- git: "https://x-access-token:{{env_var('GITHUB_ACCESS_TOKEN')}}@github.com/example_org/dbt_domain_exmaple1.git"
revision: main # tag or branch name
warn-unpinned: false
- git: "https://x-access-token:{{env_var('GITHUB_ACCESS_TOKEN')}}@github.com/example_org/dbt_domain_exmaple2.git"
revision: main # tag or branch name
warn-unpinned: falseEach dbt data model is typically managed in separated GitHub repositories. version and revision are available in a file for version control.
version: version number if package is hosted on https://hub.getdbt.com/revision: GitHub branch name, tagged release, specific commit (Support only full 40-character hash)
If each GitHub repository is a private repository, url should be started with https://x-access-token:{{env_var('GITHUB_ACCESS_TOKEN')}}@github.com/ (No need to use ssh:// because dbt doesn’t push to remote).
The access token can be generated through either approach.
Personal access token - Managing your personal access tokens
GitHub Apps access token - Generating an installation access token for a GitHub App
Updating
dbt_project/dbt_project.ymlis required to allow dbt to refer those new dbt data models.
...
model-paths: ["models", "dbt_packages/*/models"]- Additionally, we updated
td_wf_project/scripts/dbt_wrapper.pyto include thedepscommand before running models. This ensures that required packages are installed in thedbt_packages/directory before model execution. A caveat of invoking thedepscommand is that it changes the working directory, which can cause python tasks to fail during local runs. Therefore, it is necessary to reset the working directory after runningdeps.
import os
import sys
os.system(f"{sys.executable} -m pip install dbt-core==1.6.6 dbt-trino==1.6.2")
from dbt.cli.main import dbtRunner
DEFAULT_COMMANDS = ','.join([
'deps',
'run',
])
def invoke(dbt_commands=DEFAULT_COMMANDS, **kwargs):
for cmd in dbt_commands.split(','):
cwd = os.getcwd()
dbtRunner().invoke([
*(cmd.split()),
'--project-dir', './dbt_project',
'--profiles-dir', './dbt_profiles',
],
**{
k.removeprefix('dbt_'): eval(v)
for k, v in kwargs.items()
if k.startswith('dbt_')
})
os.chdir(cwd) # Work-around https://github.com/treasure-data/digdag/issues/731Data lineage is one of useful feature of dbt. As described in dbt web site, size and complexity of recent data pipeline is growing. It's becoming hard to understand their schema, relationships.
dbt provides some solutions based on your model definitions.
- A visual graph (DAG) of sequential workflows at the data set or column level
- A data catalog of data asset origins, owners, definitions, and policies
Document can be generated with the below command.
$ digdag run dbt_exec_workflow.dig \
--param dbt_commands='docs generate' \
--param dbt_empty_catalog=True \
--param dbt_target_path='"../docs/"'Run local HTTP server and open http://localhost:8000 with web browser to see dbt document in local.
$ python -m http.server 8000 -d ./docs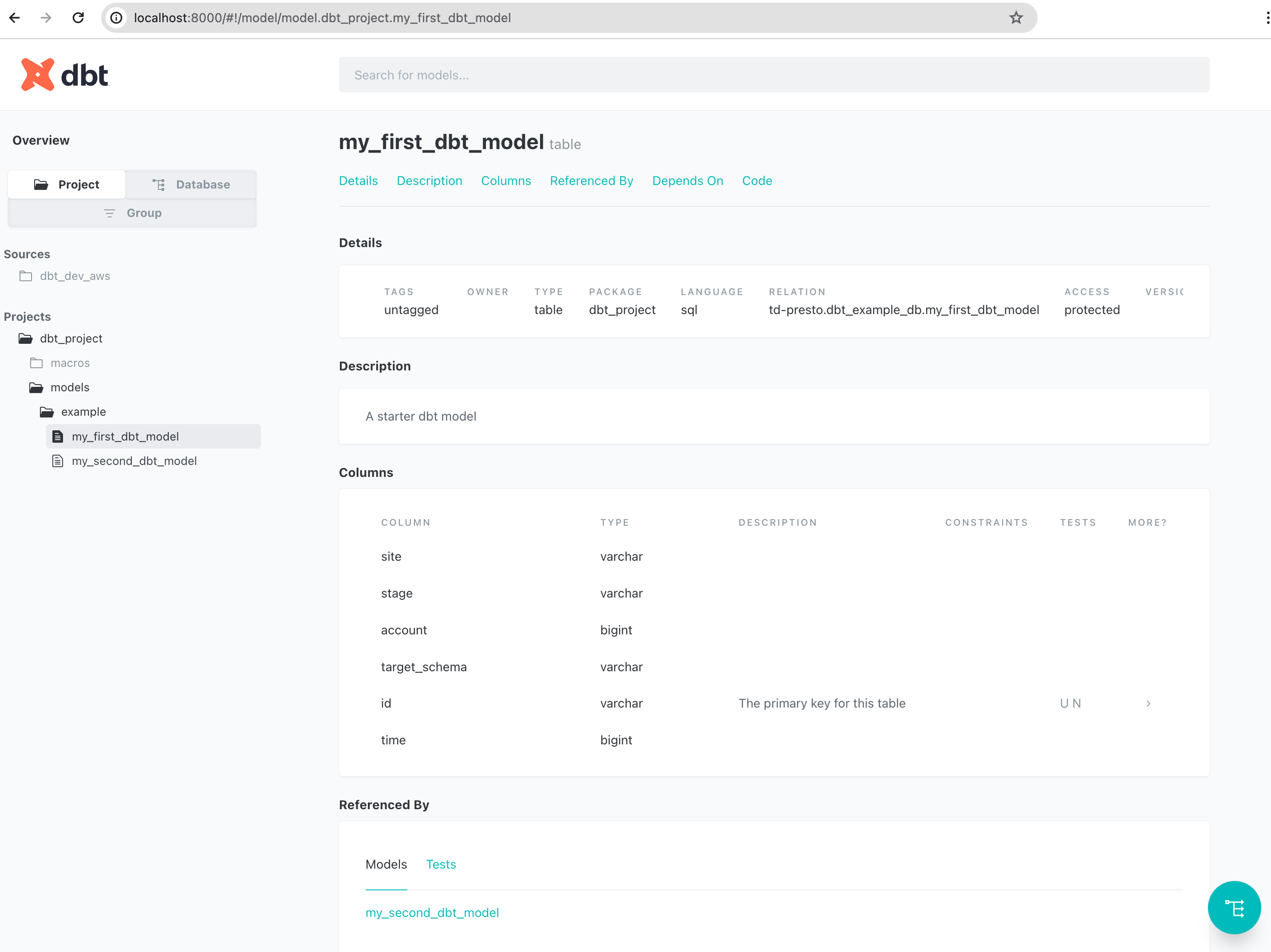
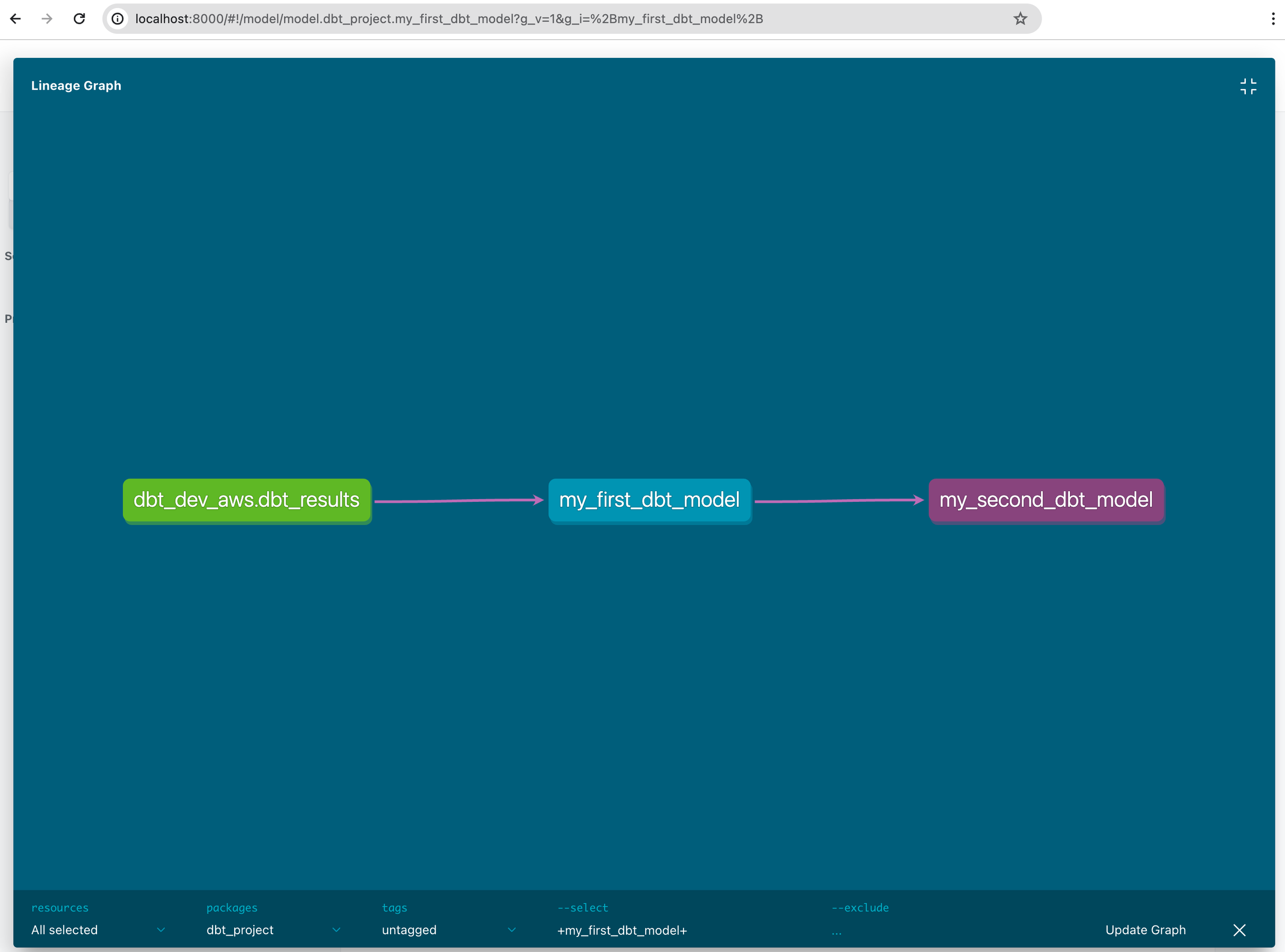
Lineage graph is shown by clicking “View Lineage Graph” at the right bottom in pages
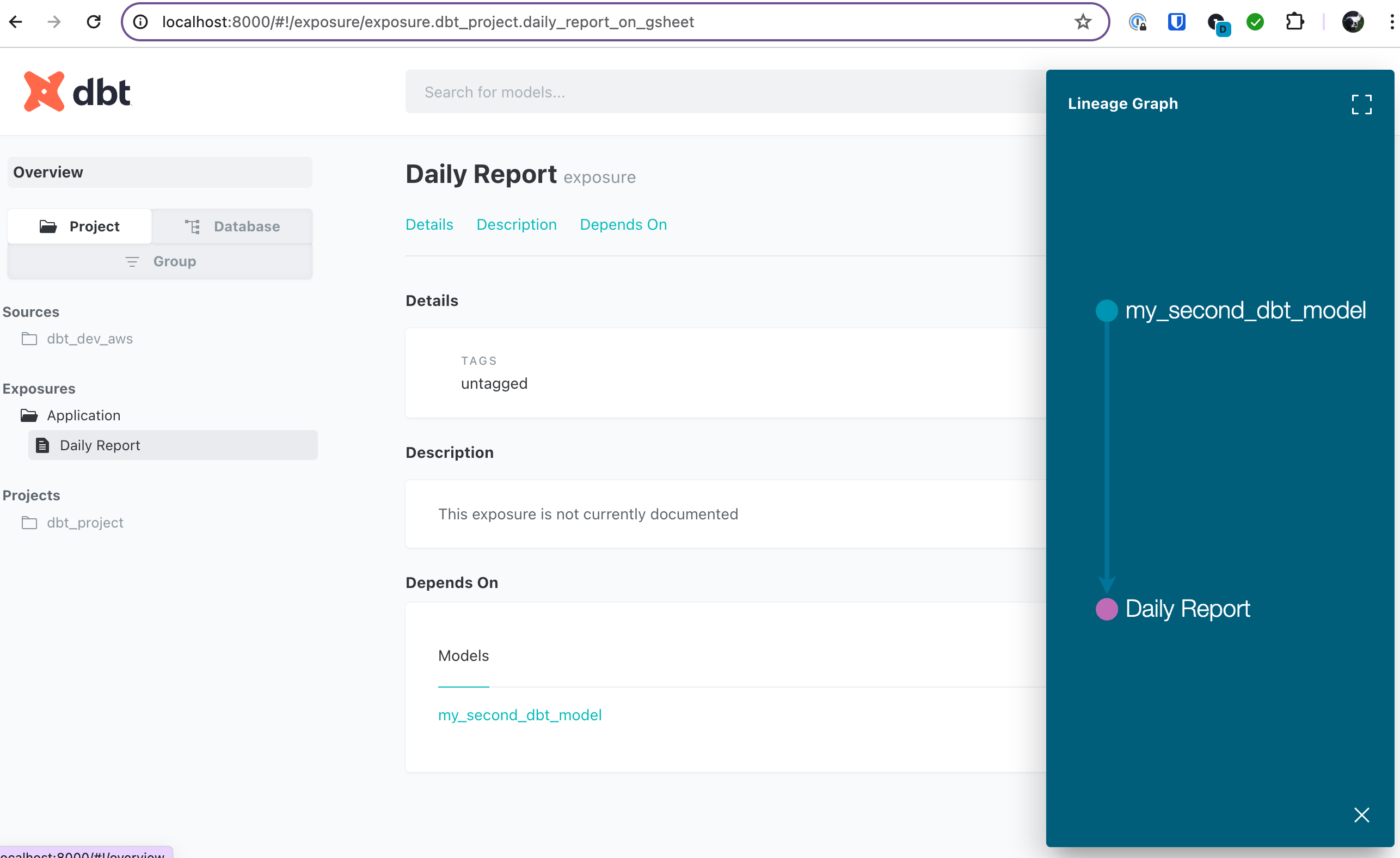
dbt allows us to define exposures in DAG which shows dependencies from external BI tools, etc.
For example, if there is a Google Sheets which is referring my_second_dbt_model, we can define dependencies in exposures.yml.
- Add
td_wf_project/dbt_project/models/example/my_first_exposures.yml
exposures:
- name: daily_report_on_gsheet
label: Daily Report
type: application
maturity: medium
url: https://docs.google.com/spreadsheets/d/ABCDEFGHIJKLMN/edit#gid=123456789
depends_on:
- ref('my_second_dbt_model')
owner:
name: Data TeamNew exposure definition is added in DAG.
Let’s share dbt document with team members. It should improve visibility of data pipeline and team collaboration. There are some candidate locations to host dbt document like GitHub pages, S3 static hosting.
This CircleCI config.yml executes docs generate command when pull request is merged into main branch on GitHub. The artifact will be committed into gh-pages branch to avoid commit history of main branch is flooded with commits by CI. Including [ci skip] in commit message blocks CI build on gh-pages branch.
version: 2
jobs:
make_build_docs:
docker:
- image: cimg/openjdk:11.0.21
steps:
- checkout
- run:
name: Install Digdag
command: |
java --version
mkdir -p ~/bin/
curl -o ~/bin/digdag -L "https://dl.digdag.io/digdag-latest"
chmod +x ~/bin/digdag
echo 'export PATH="$HOME/bin:$PATH"' >> $BASH_ENV
digdag --version
- run:
name: Install Python packages
command: |
sudo apt-get update
sudo apt-get install -y python3-pip
pip install --upgrade pip
pip install requests==2.28.2
python --version
- run:
name: Build dbt document
command: digdag run dbt_exec_workflow.dig --param dbt_commands='docs generate'
- run:
name: Deploy docs to gh-pages branch
command: |
git config user.email "ci-build@example.com"
git config user.name "ci-build"
git add ./docs/index.html ./docs/manifest.json ./docs/catalog.json
git commit -m "[ci skip] Publish docs for Github Pages"
git push -f origin $CIRCLE_BRANCH:gh-pages
workflows:
version: 2
check:
jobs:
- make_build_docs:
filters:
branches:
only:
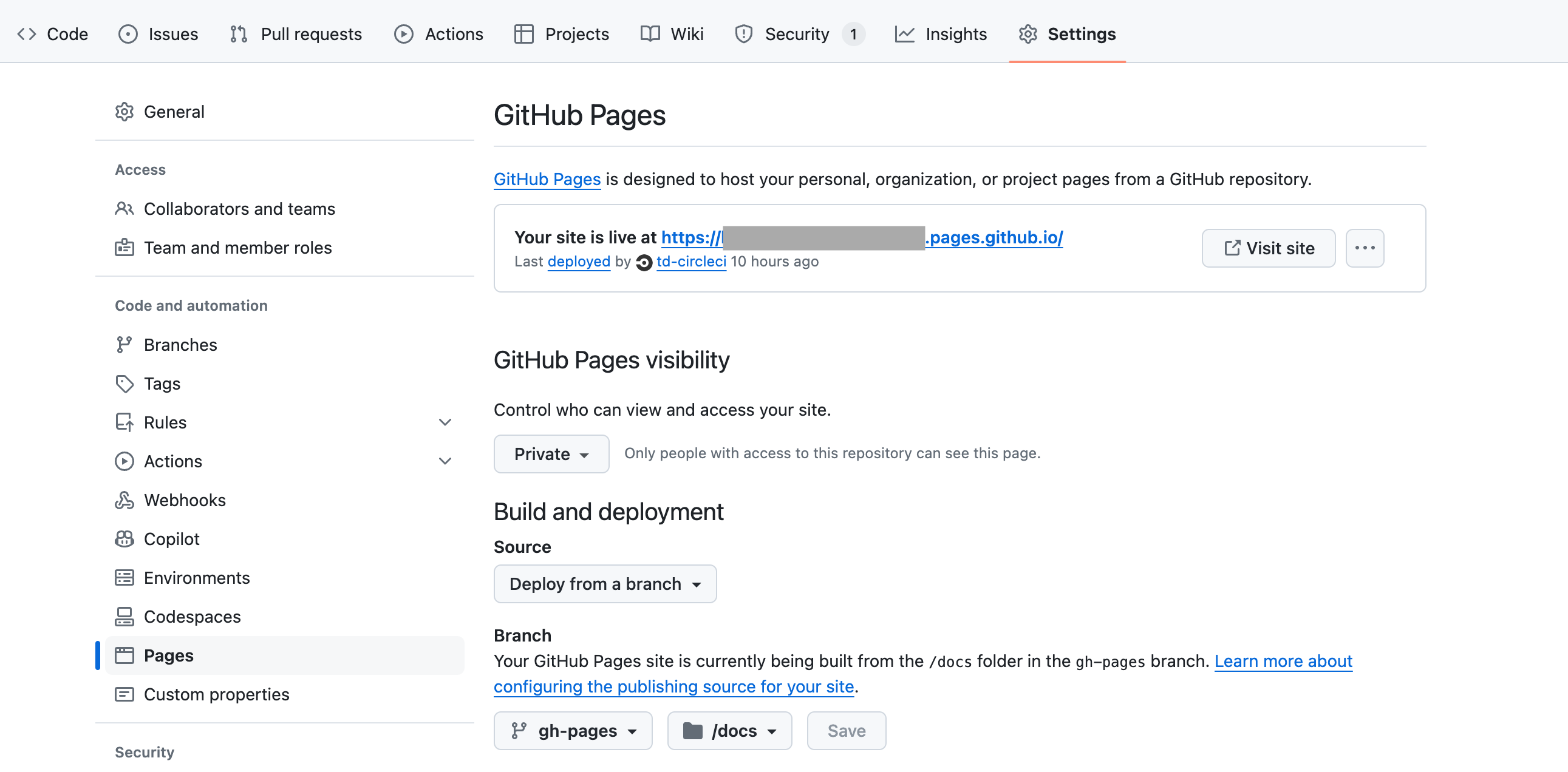
- mainVisit https://github.com/{organizaiton}/{repository}/settings/pages to configure GitHub pages.
By choosing gh-pages branch as a source of “Build and deployment”, artifacts generated by CI will be deployed to GitHub pages.
For more practices to improve observability we have not covered in this post, might be worth to share, will be put in the next episode. They include:
- Log & execution results persistence
- Writing the data testing
- Defining and tracking data quality Service-Level Objective (SLO)