At Treasure Data, we’re on a mission to radically simplify how companies use data to create connected customer experiences. Our sophisticated cloud-based Customer Data Platform (CDP) drives operational efficiency across the enterprise to deliver powerful business outcomes in a way that’s safe, flexible, and secure.
We are thrilled Gartner Magic Quadrant has recognized Treasure Data as a Leader in Customer Data Platforms for 2024! It's an honor to be acknowledged for our efforts in advancing the CDP industry with cutting-edge AI and real-time capabilities. You can get the report here.

Treasure Data CDP processes massive data for our customers. The demands of data processing are growing rapidly. Treasure Data CDP receives over 2 million rows / second in our ingestion pipeline and currently stores over 100 petabytes in PlazmaDB. The demand for the Worker Platform is also increasing and handles over 67.8 million jobs each month.
Worker Platform is an internal platform that manages the fair scheduling of jobs and helps manage the state of individual jobs within the platform while they run.
A job can be anything from a Apache Hive or Presto query to a data connectors job to an internal process doing data defragmentation. This means there are jobs that are expected to finish in a few seconds and other jobs that need to run for days, so the Worker Platform needs to be able to handle a fairly diverse set of problems. A job is run by the client and the client is run by the Worker Platform.

Previously, a job had been tied together with a process that ran on both the client's instance and the Worker Platform. After a job is started, a worker process continually monitors its status, resembling the rhythm of a heartbeat. It retrieves the job status code, manages retries, and communicates the state to the API responsible for job status management. The worker process continues until the job finishes. And also, if an instance had gone suddenly due to being unhealthy, the jobs that ran there also failed or were retried. We had to monitor which instances were running which jobs and track the scope of impact.
Because of this connection, the instance couldn’t be shut down if even one job was running. We had to wait for all jobs to finish and do some manual operations when we terminate the instance. In addition, we estimated that 30 jobs can be run at one instance, but it didn’t run 30 jobs all time.
Container technology is one of the system virtualization and isolation technologies, and becoming widely used recently. We can package both application and its runtime environment as a container image then deploy it in a container platform.
The isolation of application runtime improves security, stability, and development efficiency of application. In addition, we can easily scale-in or -out in the container platform to optimize the running cost.
Worker Platform runs many types of jobs and the applications of jobs are maintained by multiple teams. So the container technology is optimal for the Worker Platform. We selected Amazon EKS (Elastic Kubernetes Service) as the container platform to reduce our operation work to manage a container platform.
Worker7 and its predecessors were all built on Ruby and a library called PerfectQueue (PQ) and manages each job as a forked process. PerfectQueue supports account based queue isolation and has some fair scheduling capabilities based on account level concurrency limits. Each job process connects to its RDS (Relational Database Service) with a single connection each and tries to take a table lock on the scheduling table then attempts to schedule a job using a series of SQL (Structured Query Language) queries. While the job is running each of these processes reconnects to the RDS and updates a timeout timestamp. Once the job finishes, it similarly marks it as done by connecting to the RDS and updating its record as finished, and then, it callbacks job status to API.
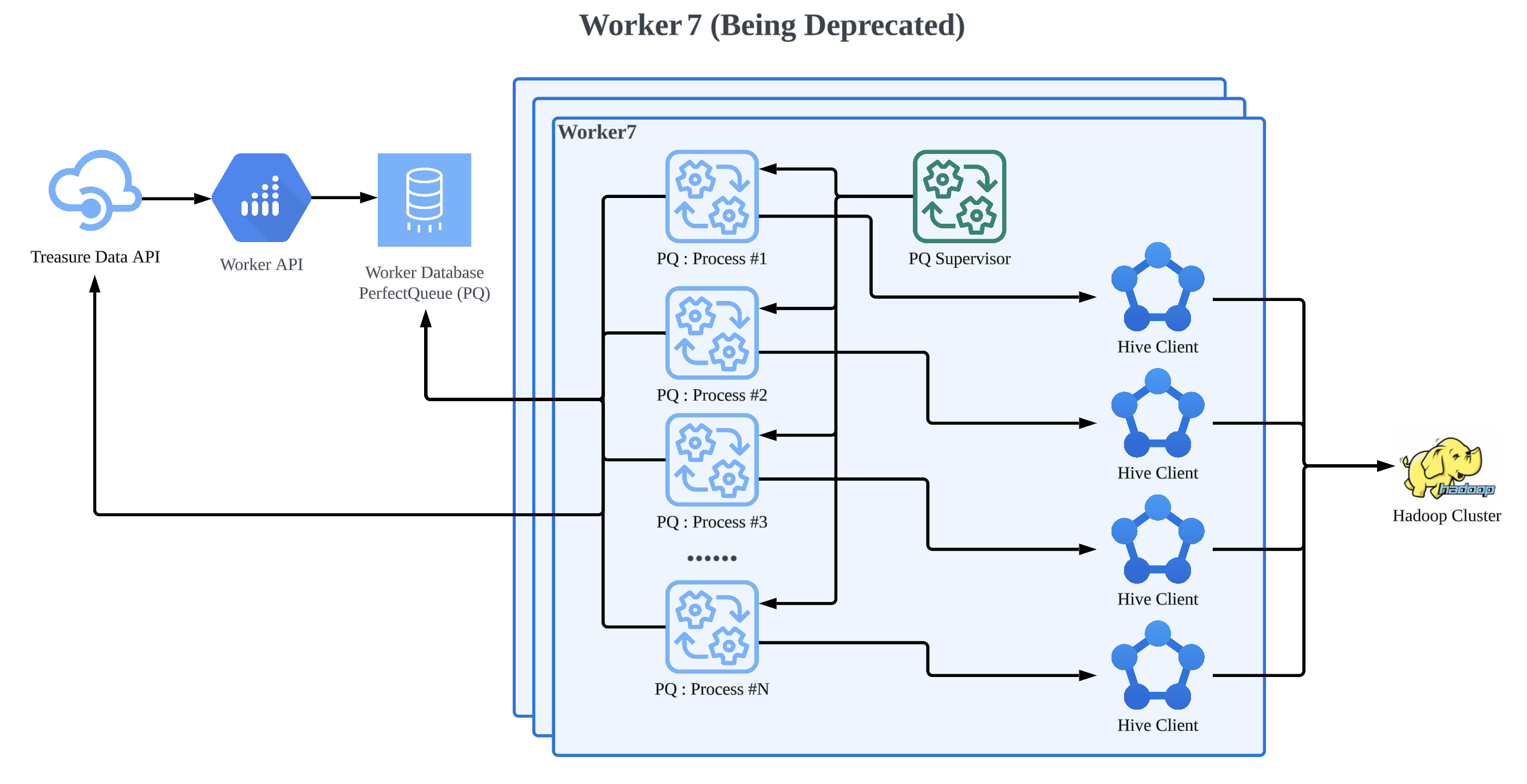
Some of the issues we have encountered running this system at scale were:
- RDS connection exhaustion due to too many processes trying to connect to a single instance at the same time.
- Lock contention issues due to too many processes attempting to table lock a single table.
- Noisy Neighbor issues where a heavy job might impact performance of other jobs running on the same node.
- Service lifecycle limitations due to the stateful nature of running jobs (it can take days to safely shut down an instance).
- Job type centric code lives in the jobs management system leading to hard to manage releases due to cross teams' ownership.
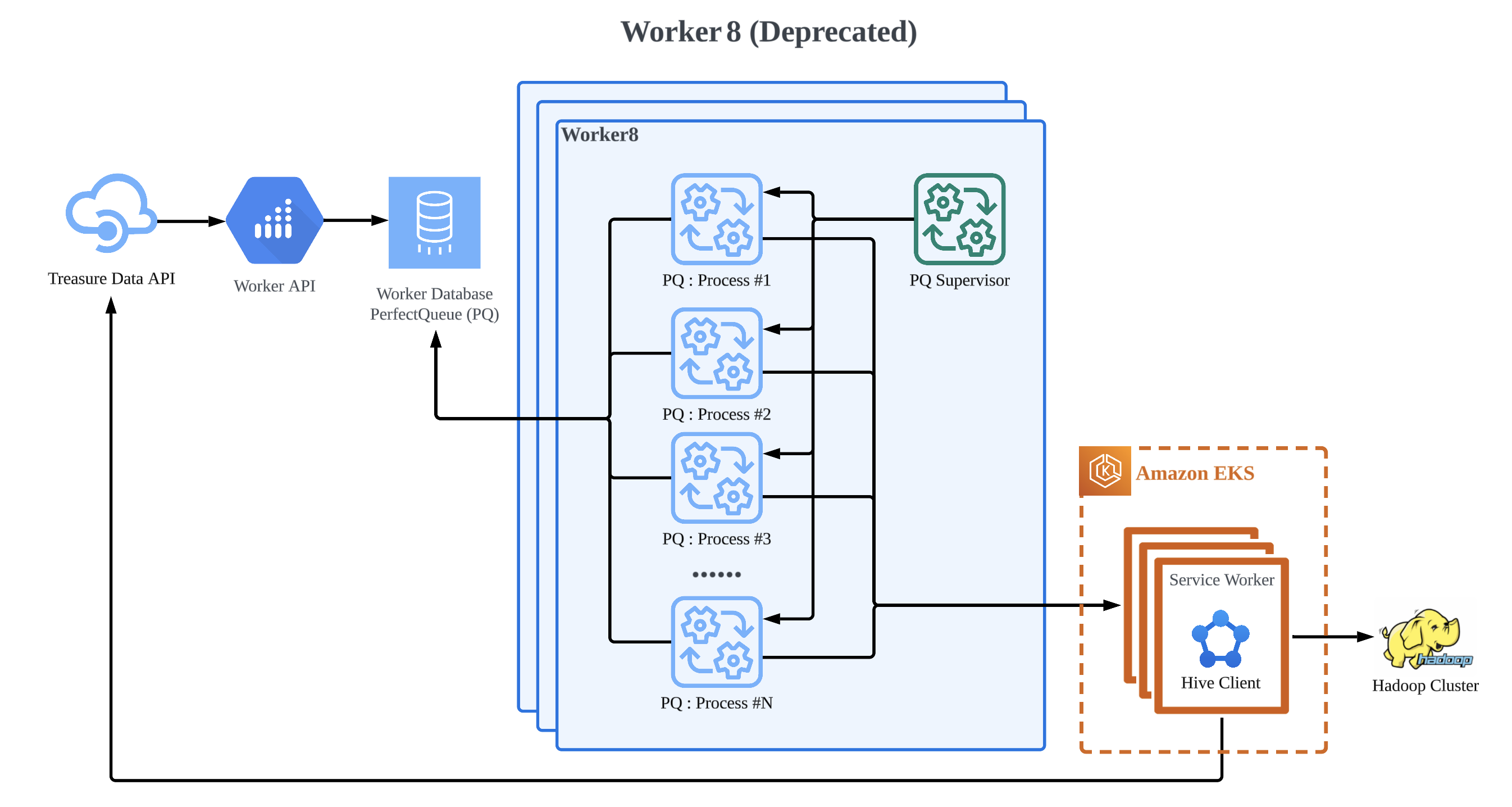
Worker8 was an incremental evolution from Worker7 where a big chunk of the code was used as is, but job processes were moved from running in a forked process to being running in Amazon EKS. This means it’s still built on Ruby and PerfectQueue and shares many of the shortcomings of Worker7, like a per process state making service life cycles hard to manage. It also introduces a new issue of slower startup times of jobs, since it takes longer to start a Pod in Amazon EKS than it does to start a subprocess on the same node. It does improve on the Noisy Neighbor issue and team level code isolation issue though since that is now mostly handled by Amazon EKS isolation. In Worker8, codes were decoupled between the Worker system and the dedicated ones for each job type (Hive, etc). Therefore, the ownership boundary has been clearer and it made easy maintenance such as the test and the deployment.
In addition, the Apache Hadoop client moved to the Worker8 platform from Worker7, and then, it was the service-worker from the Hive client server which uses state management with Raft algorithm. In Worker7, it had the same problem that a process tied together with a job, so that instance also couldn’t shutdown if even one job was running there. Thanks to Amazon EKS, it was able to scale-out / scale-in the client in Amazon EKS node using Cluster Autoscaler. But at this time, the Worker Platform still couldn’t do that.
Thanks to Worker8, the client moved to the container-based environment on Amazon EKS and it started to be able to scale-out automatically, and each software engineer was able to focus on service themselves. At this time, some of the issues that we had encountered in Worker7 remained, but this was a big step in the Worker Platform since this step was continued for the next one.
Worker9 is a total rewrite from Worker8 supporting the same contracts, but written in Kotlin and designed as a set of event-based microservices. It consists of some services which are worker-scheduler, worker-executor, and worker-cleaner. And also, some codes are commonized that are to be re-use for each service. Each service has a pool of coroutines that processes events from Amazon SQS (Simple Queue Service) and for events that need to be processed again they are resubmitted to Amazon SQS, after being processed for its next action a few seconds later. This removes all the issues of long standing state in each node, since it’s offloaded to Amazon SQS making process management significantly simpler and making the overall system a lot more fault tolerant.
While the scheduling uses a port of the original PerfectQueue used in Worker7 and Worker8, there has been one significant improvement in this iteration which is that instead of having just 1 job scheduled per connecting processes, the new scheduling service will try to schedule up to 100 jobs at the same time and queue them up as events in Amazon SQS for the worker-executor to start and manage as jobs in Amazon EKS. The pain point still persistent in this version of Worker Platform is the relatively high latency for job startup since it involves starting a Pod in Amazon EKS cluster.
In the worker-executor, the process doesn’t tie together with the job because the event in Amazon SQS has the status. The process fetches the event from there, it just handles an event based on that status, after that enqueues an event to Amazon SQS. Thanks to Amazon SQS and the event’s state, we were able to decouple the process and the job, and then we don’t need to have the process spaces as much as max number of executable jobs.
The rough flow of how the worker-executor works.
- Fetch an event from Amazon SQS and check the status of it.
NEW: Submit a Pod as a job to Amazon EKS to run a job and enqueue an event to Amazon SQS withRUNNINGstatus.RUNNING: Check the Pod status on Amazon EKS.- Running: It enqueues an event to Amazon SQS and sends the heartbeat to
worker-apiat regular intervals to indicate "this job is running" (this is to block rescheduling the same job fromworker-scheduler). - Error: Send a request to
worker-apito indicate "this job has an error or can be retry". - Completed: It sends an event to Amazon SQS with
CLEANUPstatus.
- Running: It enqueues an event to Amazon SQS and sends the heartbeat to
The finished event will be sent to Amazon SQS for cleanup, it will be used to clean up the finished Pods from Amazon EKS including related data (metadata) by worker-cleaner. The Amazon SQS was decoupled into processed and finished to separate workload between the execution and cleanup. Which means, the responsibility has been decoupled, like worker-executor only handles the events in Amazon SQS for processing and worker-cleaner only handles ones in Amazon SQS for cleanup.
And also, thanks to the event-based workflow, an event isn’t handled by a dedicated process of worker-executor, so when we maintain an instance, it can be terminated and started whenever then it gives flexible scaling.
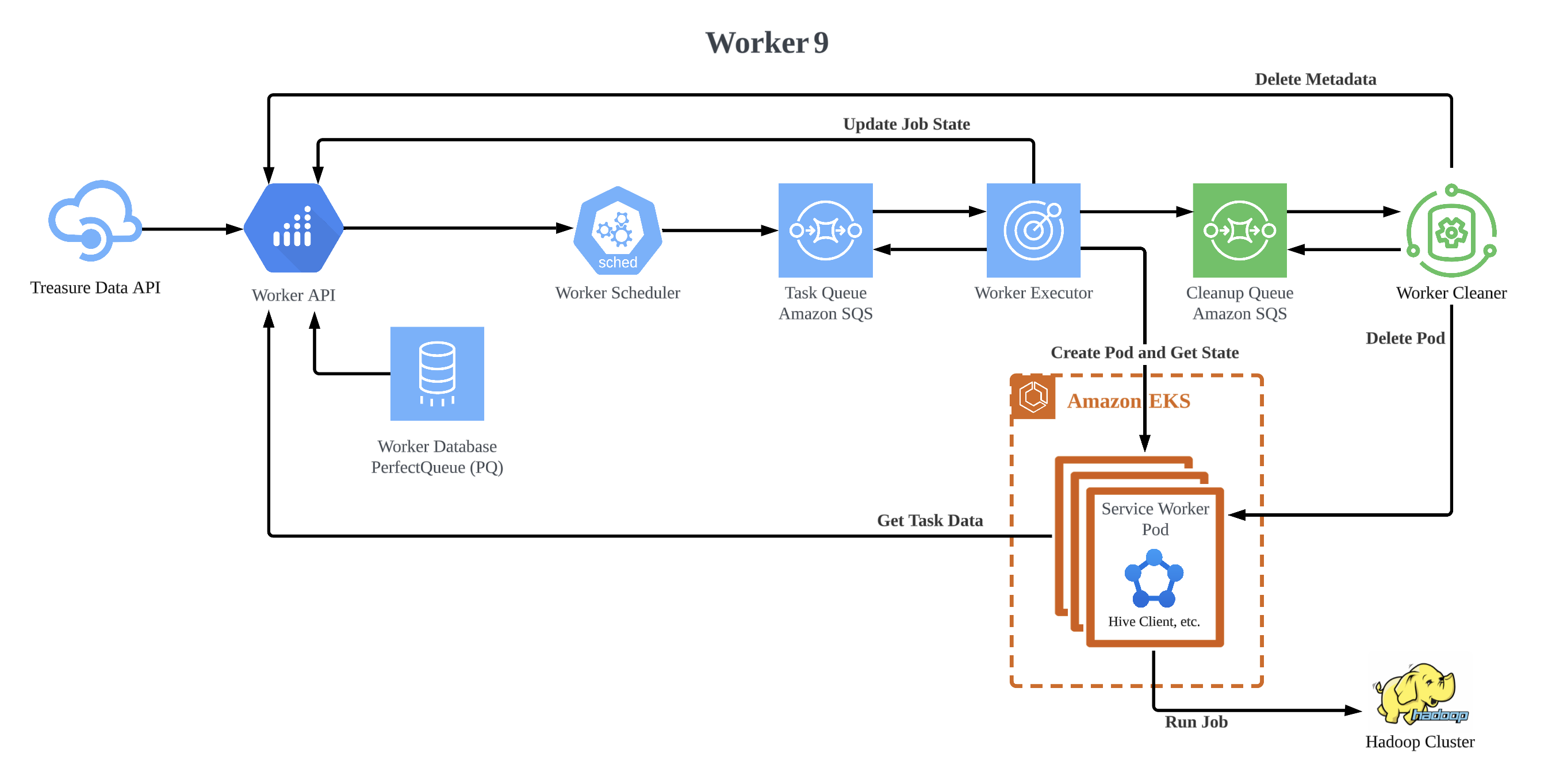
Worker9 overcomes the following challenges:
- The scheduler can fetch the chunk of jobs per process.
- The system can recover soon even if some instances have gone suddenly, no more failed or retried jobs due to unhealthy instances.
- The instance can be scaled-out / scaled-in automatically based on the workload of the amount of events in Amazon SQS or jobs in database because a process doesn’t need to keep taking care of a specific job anymore.
- Flexible scaling reduces cost, so the huge computing power which has unused time isn’t needed to keep holding.
- The maintenance has been easy due to the services being decoupled based on responsibilities and common codes are shared, the software engineer can focus on only a service when they maintain a service.
Next step was to deal with the high latency for job startup in Amazon EKS. To do this, we chose the approach of having containers boot and pre-process ahead of time, then receive work once ready to process it. To do so we had to make changes to the service-worker container protocol and ask each service owner to update their applications to be able to run on the new protocol. Also we introduced a container reservation system which is called as worker-reserver that manages pre-forking of containers based on a combination of historical usage patterns and current needs. We also introduced a sidecar to run together with each job container specifying what each service-worker has to manage when integrating with the system. While this takes care of one of the last major outstanding issues in the Worker Platform which is the high latency for job startup, it also introduces a lot of complexity in the platform as well as more places and ways that the system can break.
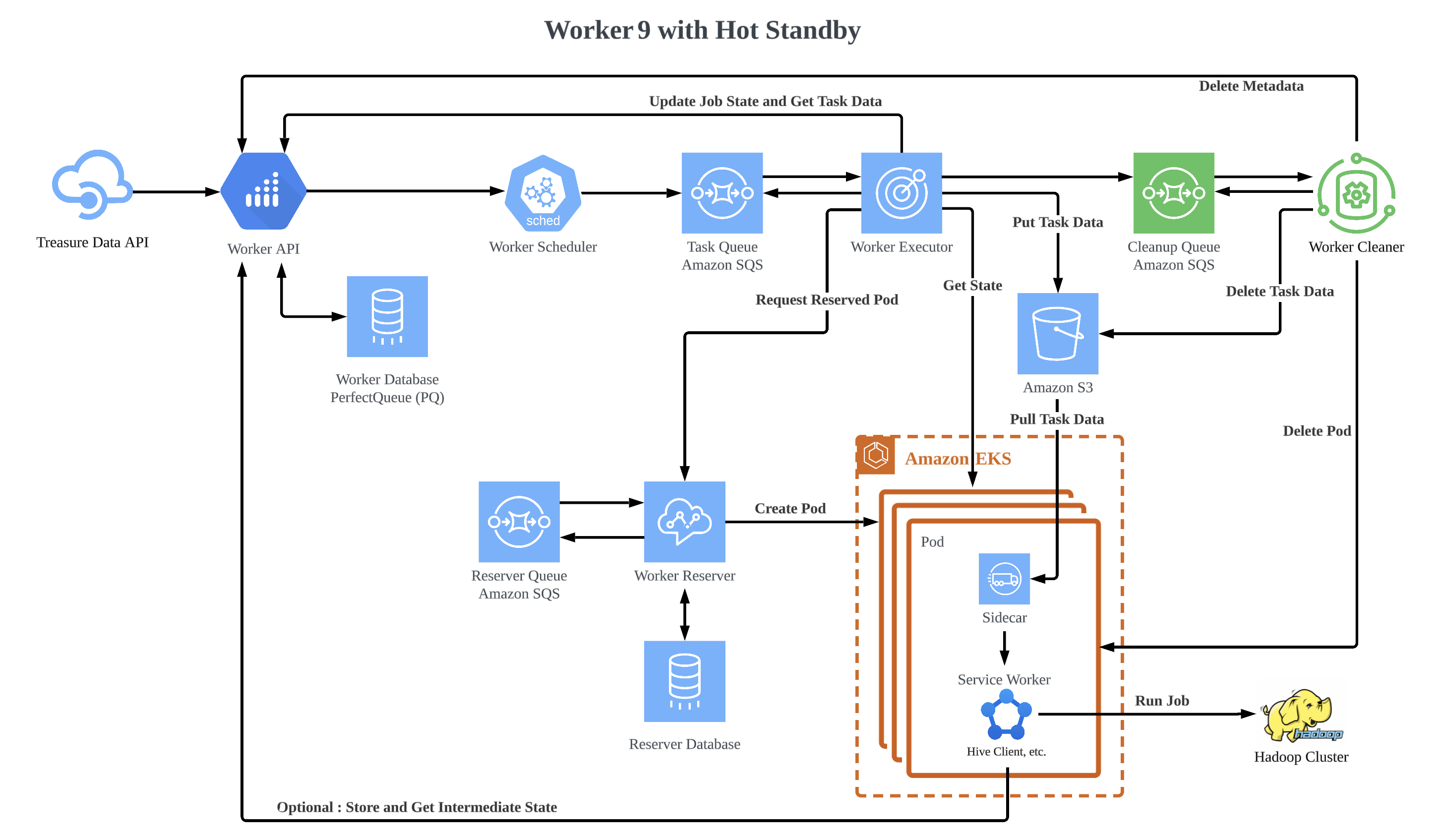
The rough flow of how the hot standby works.
- The
worker-reservergets past metrics and calculates how many jobs (Pods) are needed at this time, and creates Pods.- The job isn’t assigned yet even if the Pod is started, so the
service-workerin the Pod waits until assigned and thesidecarprocess in the Pod is polling the job data from Amazon S3 (Simple Storage Service).
- The job isn’t assigned yet even if the Pod is started, so the
- The
worker-executorrequests a Pod toworker-reserverwhen a job comes, after getting a Pod name, it pushes the job data to Amazon S3.- If no readied Pod,
worker-reservercreates a new Pod and returns that Pod name.worker-executorrepeats requests for a while to see whether the Pod has been booted. - If another Pod has already been ready during that,
worker-reserverswaps the creating (booting) a new Pod to the readied one to reduce waiting time even a second.
- If no readied Pod,
- The
sidecarprocess downloads the job data from Amazon S3 to a specific path which is shared withservice-worker’s Pod by "volumeMounts" setting. - The
service-workerstarts a job as usual. - The
sidecarprocess uploadsservice-worker’s logs.
In the hot standby container, the Pod creation responsibility is moved to worker-reserver and the job assignment is achieved by exchanging job data via Amazon S3 and service-worker needs to wait until the job data is stored on a specific path. Some new components which are worker-reserver, sidecar, and the new service-worker are needed for hot standby, and the hot standby and non-hot standby environments are coexisting since for each service-worker owners need to migrate it. These made some complexities, but we had to solve the last major outstanding issue in the Worker Platform which is the high latency for job startup. Even though it’s just a few seconds, it would be the cause of the delay and impact on the entire job workflow of customers if it piles on.
Thanks to the hot standby container, the job startup time has been improved significantly. It's 10 times faster than the container that’s not the hot standby. And also, some contracts that service-worker was doing such as getting job data and uploading logs have been owned by the sidecar as common features, which means, service-worker can focus on only running the job as the client.
Worker8 introduces the container platform via Amazon EKS and it supports isolation of application / job in Worker Platform. It improves security and stability of the platform and resolves issues like Noisy Neighbor problems which one heavy job could impact others on the same instance. In addition, it improves the ownership boundary between the platform and application of each job.
Worker9 introduces microservices architecture with event-based processing via Amazon SQS. It improves the system resiliency, scalability, and maintainability of Worker Platform. In addition, the hot standby containers feature improves startup time problems caused by the introduction of the container platform.
These evolutions improves stability, cost efficiency, maintainability and productivity of the Worker Platform. As a result, the software engineers are able to focus on development of new features.
The container technology is not a Silver Bullet. We need to improve some issues caused by the introduction of container technology. However, proper adoption of the container technology provides advantages of isolation, scalability, reliability, maintainability, and cost.