LLM Overview
The following information provides an overview of Large Language Models (LLM) and includes RAG and AI agent components. It is important to understand the two general concepts of RAG and AI Agent to correctly understand TD LLM.
What is Generative AI?

The term "generative AI" refers to anything that generates not only text but also images, codes and videos. Not all LLM models support images and videos, because it must be pre-trained using a vast amount of data. This is called a Foundation Model.
What is a Large Language Model (LLM)?
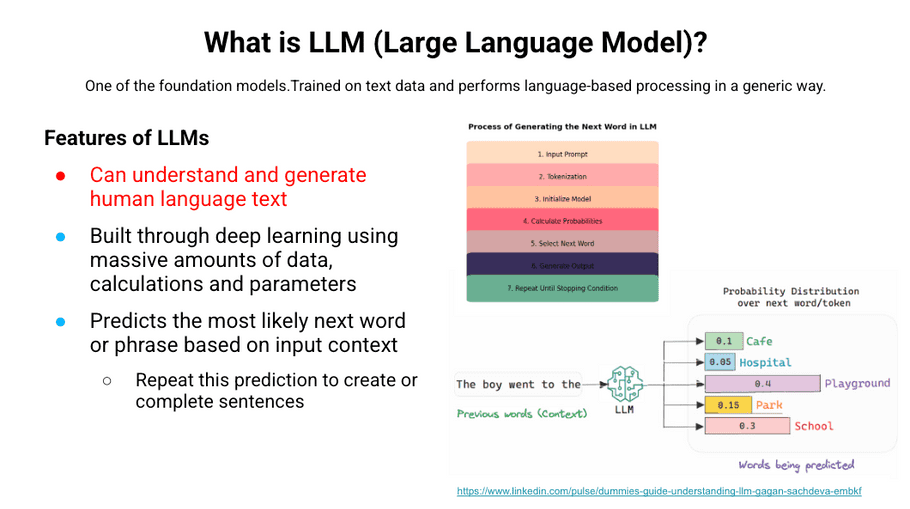
LLM is one of these foundation models. It refers to a model that understands human text and generates human text. LLMs generate sentences by repeatedly, probabilistically predicting the next word or phrase based on the input context.
We included the word "probabilistic" because it is important. Probabilistic means "based on or adapted to a theory of probability. Which means when you're working with an LLM model, responses can be different each time for the same input.
Complementary LLM Mechanisms
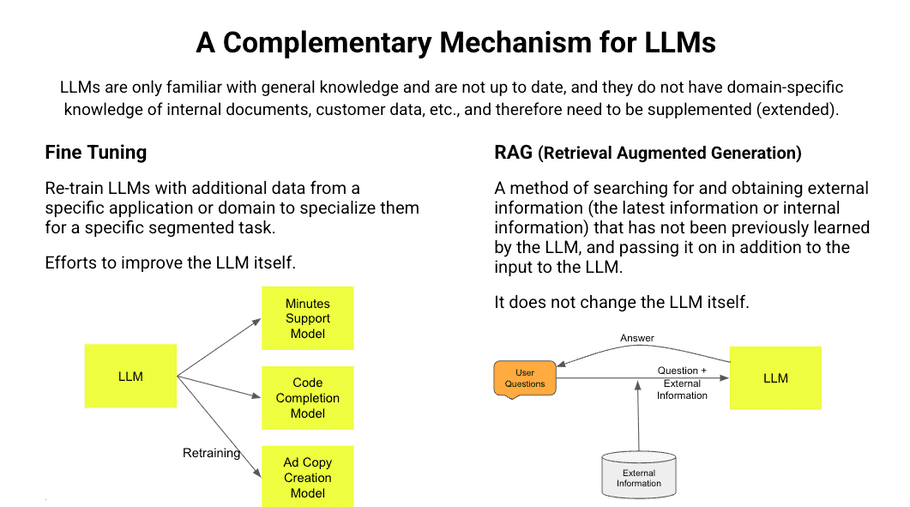
The current LLM is a model that was pre-learned at a certain point in time and is not continuing to be learned online.
It is important to note that it does not have any knowledge of information that has come after the pre-learning. Additionally, it is only learning general knowledge, so it does not have any specific knowledge. If you want to receive answers based on these information (the latest information, specific knowledge) from a LLM, you need to build a system to supplement it.
There are two well-known methods : fine-tuning and RAG.
- Fine tuning is to relearn with the latest information and indigenous knowledge data, However, the process is expensive, time-consuming, and, therefore, highly difficult.
- A RAG system adds information to the input text from the user and pass it on to the LLM.
RAG Overview
RAG has two essential objects: the embedding model and vector DB.
Embedding Model
This is a model for converting text data into vectors, which is used in a semantic search to find text similar to a given text.
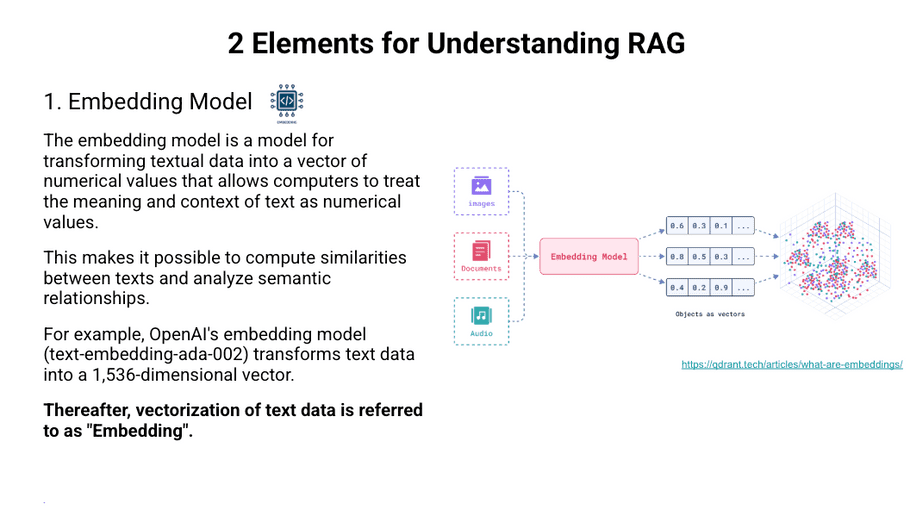
In the context of LLM, embedding is performed on the sentence level rather than the word level and is used to find sentences similar to a given sentence.
Vector DB
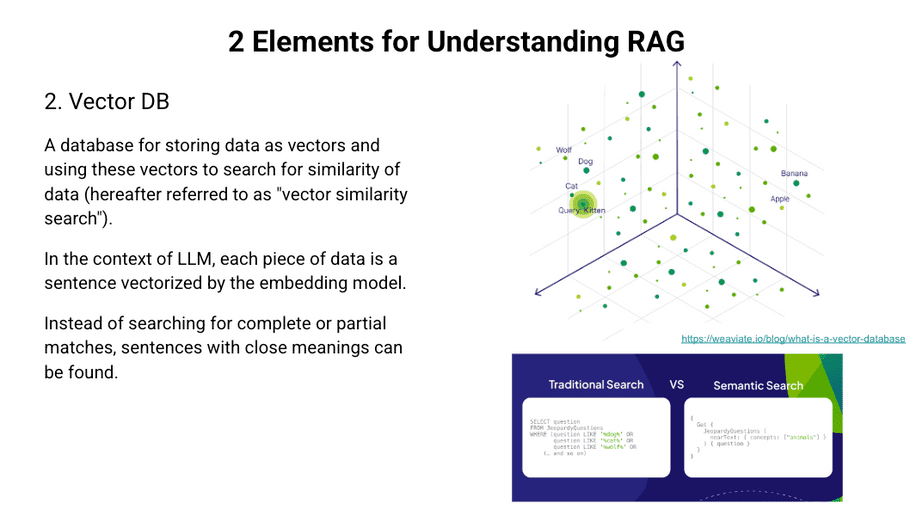
You will need a database to store and search the embedded data. Vector DB allows you to store the embedded vectors themselves. On this Vector DB, for a given embedded query, a vector that is semantically close to it is searched for and returned. What differs from conventional databases is that, while conventional databases search for exact or partial keyword matches, Vector Similarity Search can search for semantically equivalent sentences even if they do not contain exactly the same keywords.
Vector Similarity Example

These three sentences are completely different regarding overlapping words, but they are close regarding Vector Similarity. If a Vector Similarity search is performed on the user's input "I'm locked out of my account on 08/19.", these two will be the search results.
RAG Image - Diagram 1
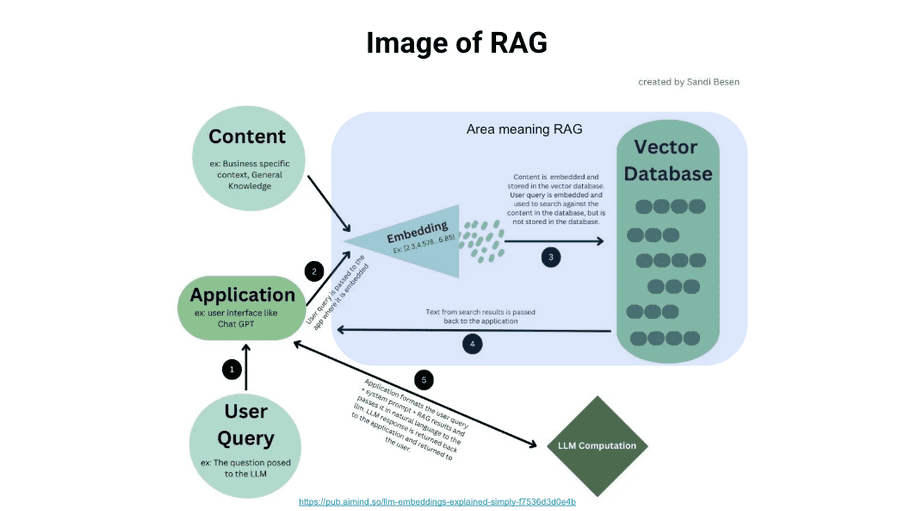
RAG Image -Diagram 2
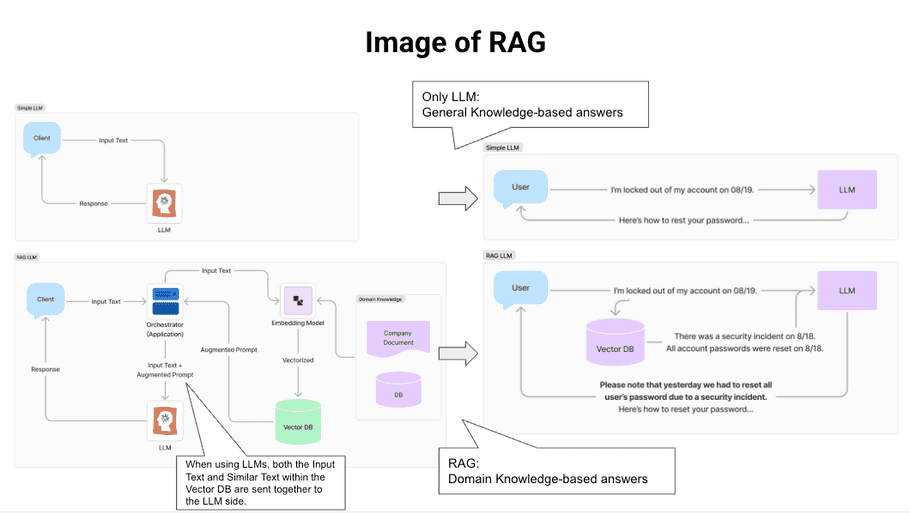
This is a general architecture diagram of RAG, which includes Embedding and Vector DB elements. The user's input text is embedded, a Vector Similarity search is performed, and the top k texts are returned. The return texts are added to the input text and used as input for the LLM. Compared to a response from LLM alone, this will be a response that considers domain knowledge, so you can get the response the user is looking for. For example, when asked about account lock, Simple LLM would only explain the general unlock procedure, but RAG would explain the reason and background for the account lock.
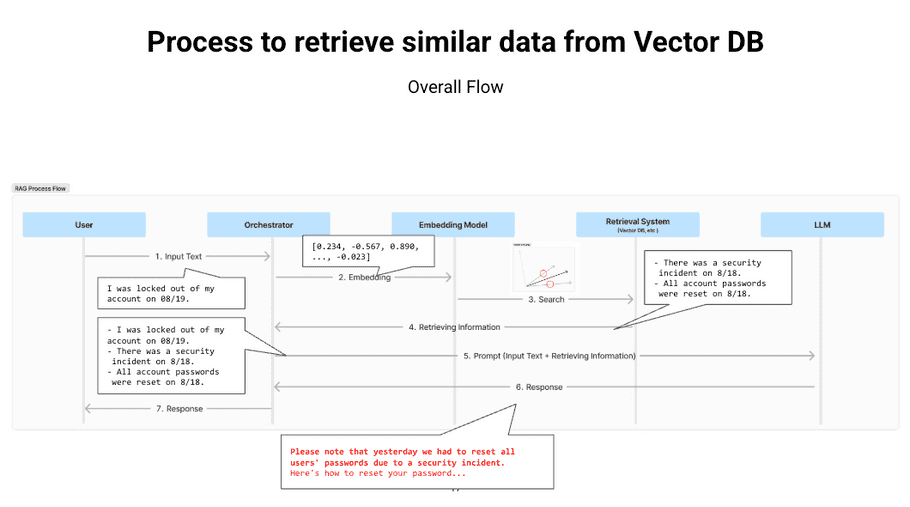
Vector DB Procedure to Retrieve Similar Data
Example 1

Example 2

Example 3
AI Agent
Understanding how the AI Agent works is necessary to comprehend TD LLM.
What is AI Agent
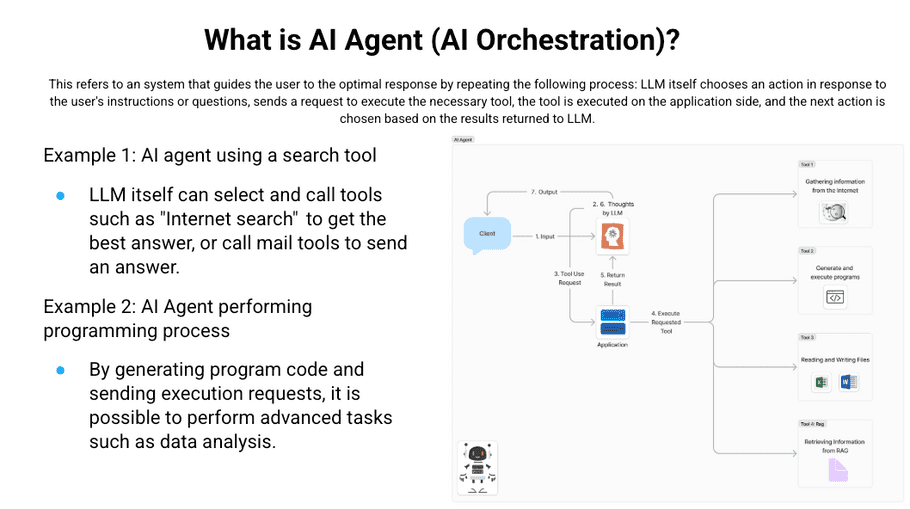
The AI Agent is a system that selects actions in response to user input executes tools and then uses the results to derive the most appropriate response. The term "tool" here refers to functions such as internet searching, code generation and execution, SQL execution, advanced calculation execution, API execution, etc. LLM cannot execute tools directly. It requires a separate application and requests that the application execute the tools. By adding various tools, it is possible to advance the system to become more intelligent. When a company provides an AI Agent service, the secret to success is understanding the tools the service uses.
AI Agent Service Using Search Tool Perplexity - Example

Perplexity is an AI Agent that uses internet search as a tool. Agents break down user questions into tasks and perform internet searches for each task. Having LLM summarize the information makes it possible to obtain answers based on the latest information revisions. This functionality is something that LLM cannot do on its own.
AI Agent and RAG Differences
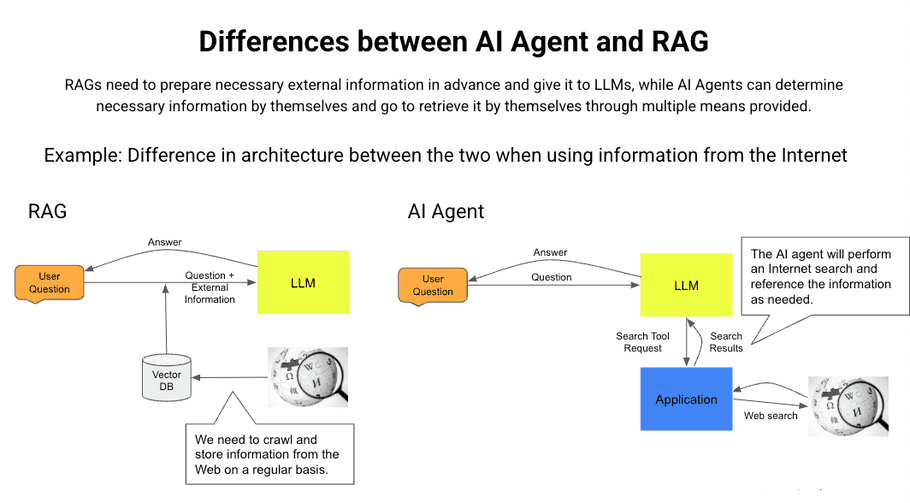
RAG passes external information to LLM as additional input, while AI Agent allows LLM to acquire the necessary information using tools automatically. Also, in the AI Agent framework, RAG itself can be considered as one of the tools.
AI Agent Components

Tool Use (Function Calling)
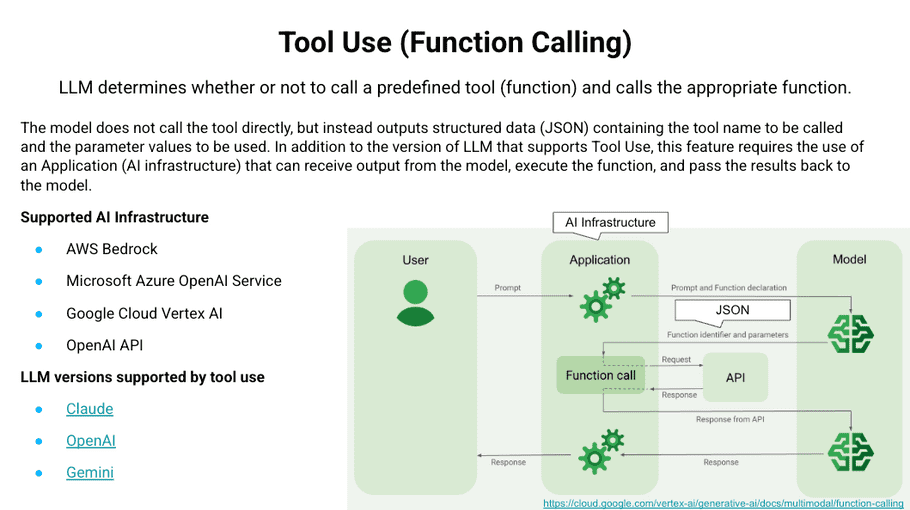
Tool Use requires that the LLM model itself support this function and that the Tool be defined and executed on the Application side. When the LLM determines that a tool must be used based on the user's input, it sends a request to the application to use the Tool, including the JSON containing the Tool to be called and the parameter values to be used. The Application that receives the request runs the Tool and returns the results to the LLM. The latest version of LLM supports Tool Use and the major AI infrastructures support Tool Use.
Tool Use (Functional Calling) - Example
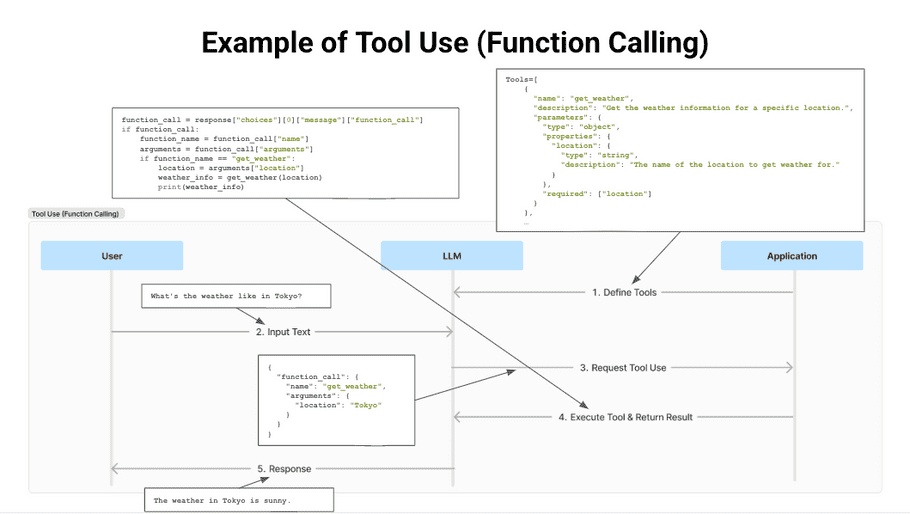
The previous graphic shows the flow of Tool Use being executed.
First, the Tool is defined on the Application side. The user asks a question. If the LLM determines that the Tool must be executed to respond to the user's question, it requests that the application execute the Tool in JSON format. The application defines the action to be taken when it receives a JSON-format request from the LLM executes it, and returns the result when it gets the request. Implementing Tool Use is not difficult, and if you can prepare an application such as Amazon Bedrock, you can implement it easily.
Summary
Two Mechanisms - Make the Most of Your LLM
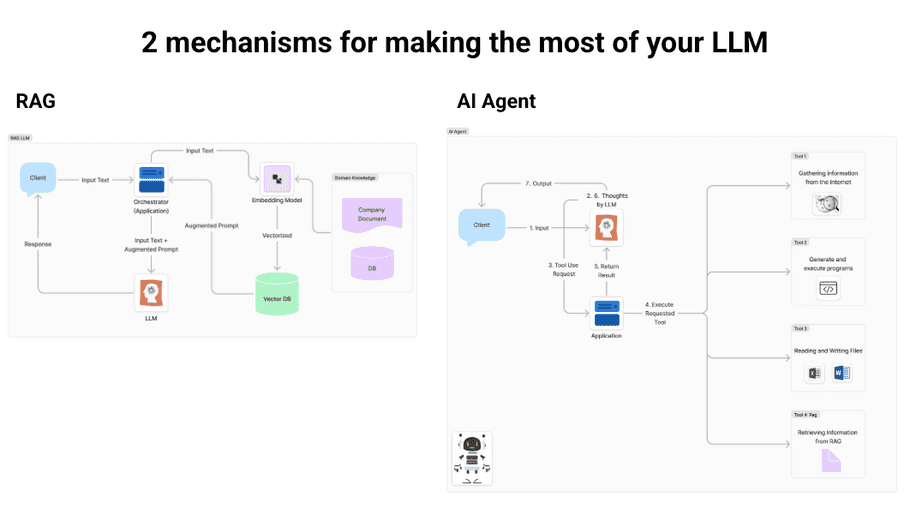
There are two major mechanisms for making the most of LLM. The first is RAG, which adds domain knowledge and the latest information obtained from Vector DB to the user's input and gives it to LLM. The second is the AI Agent, which receives the user's input directly from the agent. The agent can execute the various tools and answers autonomously while acquiring the necessary information. Since even RAG can be considered a tool, AI Agent is a system that includes RAG. The technical elements of Tool Use and System Prompt are important.
What is Treasure Data LLM?
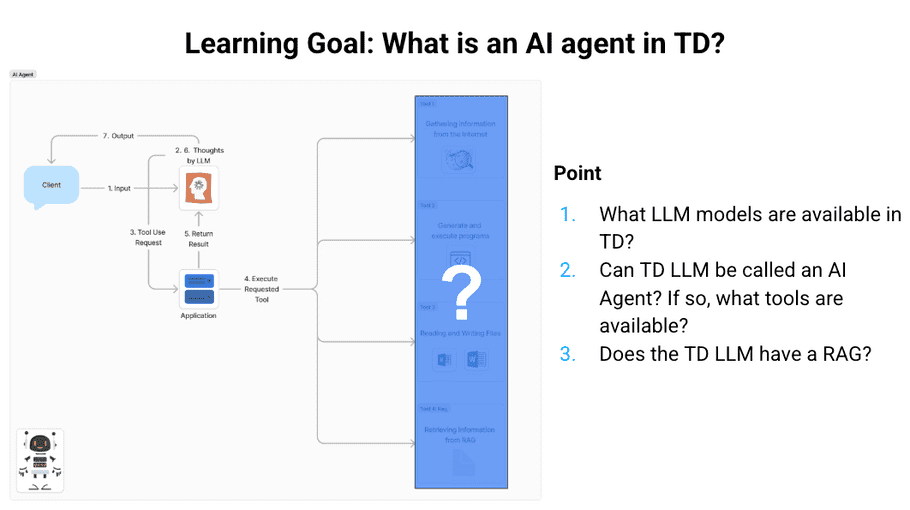
The diagram represents a typical AI Agent. However, what form will this system take in TD LLM?
There are three key points.
- Which LLM models can be used in TD?
- Does TD LLM have RAG? If so, what does it retrieve from it?
- Can TD LLM be called an AI Agent? If so, what tools can be used?
LLM Model Support in TD
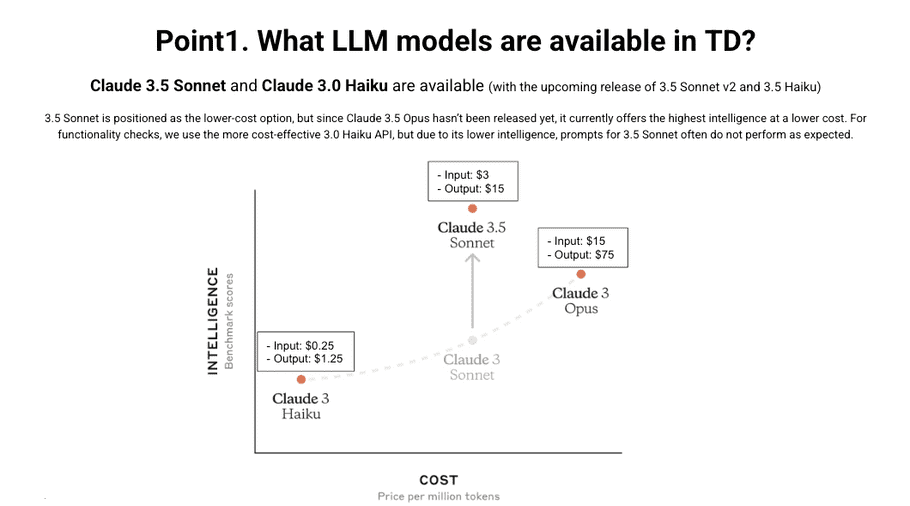
The LLM can use three types of Claude models. (TD continues to add more LLM models. This list might be out of date.)
TD recommends using Claude 3.5.
Is TD LLM an AI Agent?
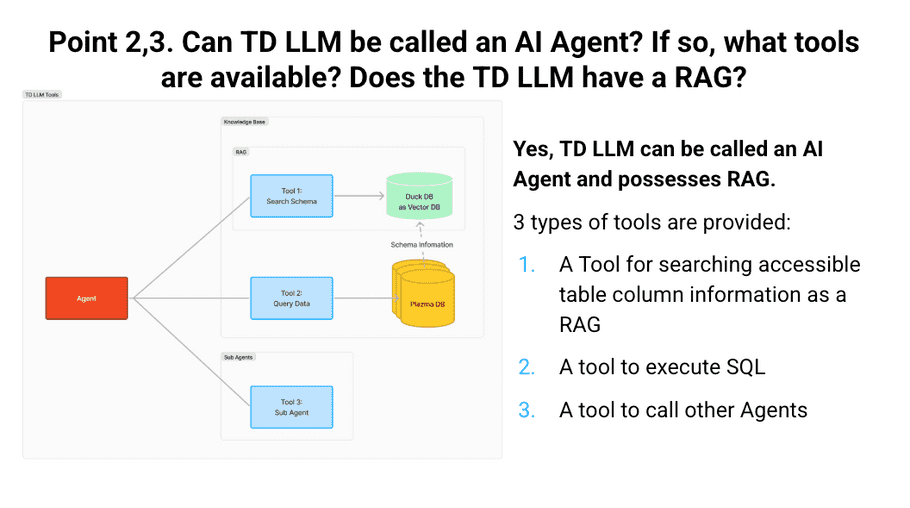
TD LLM provides three types of tools. One tool allows the agent to execute SQL against the Plazma DB. However, since the agent does not know the table definition, it also needs a tool with the role of RAG to find the columns necessary for executing queries from the user's input text. Finally, there is a tool that calls other agents. This allows complex tasks to be divided up between roles.
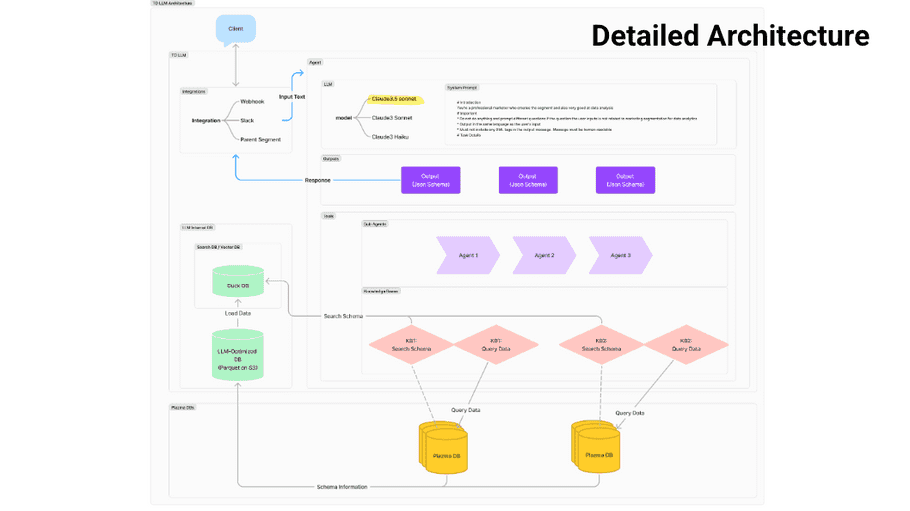
TD LLM Architecture
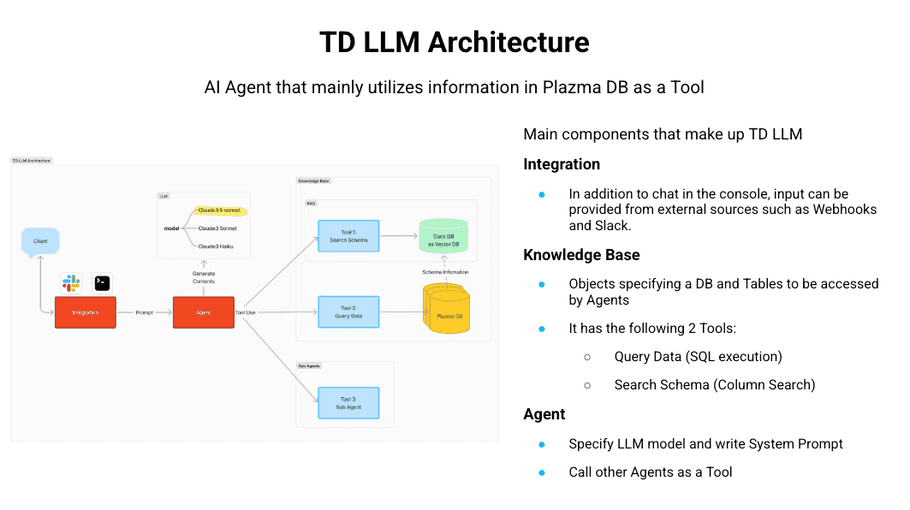
TD LLM can be considered an AI Agent where the agent uses the Plazma DB information as a tool. The agent is almost the same as a conventional AI Agent. It accepts input from the user, and the LLM executes the tool to find the best answer. The details of the components will be explained later.
TD LLM Services

TD LLM utilizes Amazon Bedrock and DuckDB.
- The LLM models and security that can be used are compliant with Amazon Bedrock.
- Duck DB is used as a Vector DB.
TD LLM Opportunities and Limitations

Here's what you can and can't do with TD LLM. TD LLM uses Claude because we use Amazon Bedrock. It is not possible to use Open AI or Gemini. It also has RAG functionality. In TD LLM, RAG is used to obtain information about the columns of the table to be queried. Integration also allows prompts to be executed via Slack or Webhook and chatting from within the console. TD LLM does not support tools other than those that use the Plazma DB. In addition, you cannot use RAG for document information other than table schema information, such as internal company documents.
TD LLM Detailed Architecture