In this page, we will explain about cases where the same person is identified by stitching together the td_client_id and td_global_id of multiple sites. Consider the following data example where there are four sites and td_client_id and td_global_id are available in all tables.
| date | site_aaa | site_aaa | site_xxx | site_xxx | site_yyy | site_yyy | site_zzz | site_zzz | ||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| month | day | td_client_id | td_global_id | td_client_id | td_global_id | td_client_id | td_global_id | td_client_id | td_global_id | |||
| 1 | 5 | aaa_001 | 3rd_001 | yyy_001 | 3rd_001 | |||||||
| 15 | aaa_001 | 3rd_002 | zzz_001 | 3rd_002 | ||||||||
| 25 | aaa_001 | 3rd_003 | ||||||||||
| 2 | 5 | aaa_001 | 3rd_004 | xxx_001 | 3rd_004 | |||||||
| 15 | xxx_001 | 3rd_005 | yyy_002 | 3rd_005 | ||||||||
| 25 | yyy_002 | 3rd_006 | zzz_003 | 3rd_006 | ||||||||
| 3 | 5 | zzz_003 | 3rd_007 | |||||||||
| 15 | xxx_002 | 3rd_008 | zzz_003 | 3rd_008 | ||||||||
| 25 | aaa_002 | 3rd_009 | xxx_002 | 3rd_009 | ||||||||
| 4 | 5 | aaa_002 | 3rd_010 | yyy_003 | 3rd_010 | |||||||
| 15 | yyy_003 | 3rd_011 | zzz_004 | 3rd_011 | ||||||||
| 25 | xxx_003 | 3rd_012 | zzz_004 | 3rd_012 | ||||||||
| 5 | 5 | aaa_003 | 3rd_013 | xxx_003 | 3rd_013 | |||||||
| 15 | aaa_003 | 3rd_014 | ||||||||||
| 25 | aaa_003 | 3rd_015 | yyy_004 | 3rd_015 | zzz_005 | 3rd_015 | ||||||
| 6 | 5 | aaa_003 | 3rd_016 | xxx_004 | 3rd_016 | |||||||
| 15 | xxx_004 | 3rd_017 | zzz_005 | 3rd_017 | ||||||||
| 25 | yyy_005 | 3rd_018 | zzz_005 | 3rd_018 |
It may appear that there are multiple users, but in fact these are cases that can be identified to just one person by connecting them with td_client_id and td_global_id across the site.
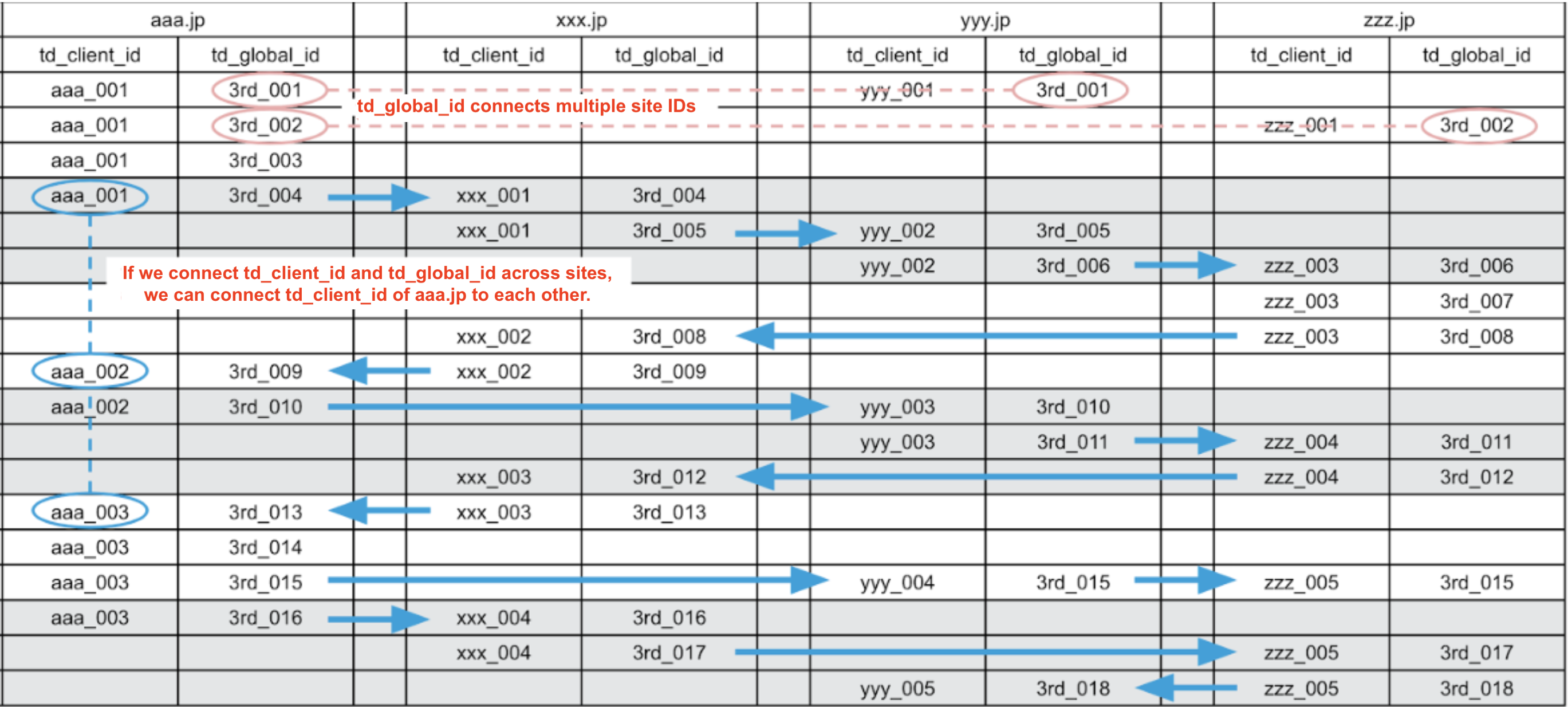
If ID Unification is performed with this data as input, only one canonical_id is expected to be generated. Let's check this in practice.
We proceed on the assumption that the above data is stored in TD tables with the names site_aaa, site_xxx, site_yyy and site_zzz for each site, as in the site_aaa table below. This table can be generated by using Workflow Samples.
| time | site | td_client_id | td_global_id |
|---|---|---|---|
| 2023/01/05 | aaa.jp | aaa_001 | 3rd_001 |
| 2023/01/15 | aaa.jp | aaa_001 | 3rd_002 |
| 2023/01/25 | aaa.jp | aaa_001 | 3rd_003 |
| 2023/02/05 | aaa.jp | aaa_001 | 3rd_004 |
| 2023/02/15 | aaa.jp | ||
| 2023/02/25 | aaa.jp | ||
| 2023/03/05 | aaa.jp | ||
| 2023/03/15 | aaa.jp | ||
| 2023/03/25 | aaa.jp | aaa_002 | 3rd_009 |
| 2023/04/05 | aaa.jp | aaa_002 | 3rd_010 |
| 2023/04/15 | aaa.jp | ||
| 2023/04/25 | aaa.jp | ||
| 2023/05/05 | aaa.jp | aaa_003 | 3rd_013 |
| 2023/05/15 | aaa.jp | aaa_003 | 3rd_014 |
| 2023/05/25 | aaa.jp | aaa_003 | 3rd_015 |
| 2023/06/05 | aaa.jp | aaa_003 | 3rd_016 |
| 2023/06/15 | aaa.jp | ||
| 2023/06/25 | aaa.jp |
| time | site | td_client_id | td_global_id |
|---|---|---|---|
| 2023/01/05 | xxx.jp | ||
| 2023/01/15 | xxx.jp | ||
| 2023/01/25 | xxx.jp | ||
| 2023/02/05 | xxx.jp | xxx_001 | 3rd_004 |
| 2023/02/15 | xxx.jp | xxx_001 | 3rd_005 |
| 2023/02/25 | xxx.jp | ||
| 2023/03/05 | xxx.jp | ||
| 2023/03/15 | xxx.jp | xxx_002 | 3rd_008 |
| 2023/03/25 | xxx.jp | xxx_002 | 3rd_009 |
| 2023/04/05 | xxx.jp | ||
| 2023/04/15 | xxx.jp | ||
| 2023/04/25 | xxx.jp | xxx_003 | 3rd_012 |
| 2023/05/05 | xxx.jp | xxx_003 | 3rd_013 |
| 2023/05/15 | xxx.jp | ||
| 2023/05/25 | xxx.jp | ||
| 2023/06/05 | xxx.jp | xxx_004 | 3rd_016 |
| 2023/06/15 | xxx.jp | xxx_004 | 3rd_017 |
| 2023/06/25 | xxx.jp |
| time | site | td_client_id | td_global_id |
|---|---|---|---|
| 2023/01/05 | yyy.jp | yyy_001 | 3rd_001 |
| 2023/01/15 | yyy.jp | ||
| 2023/01/25 | yyy.jp | ||
| 2023/02/05 | yyy.jp | ||
| 2023/02/15 | yyy.jp | yyy_002 | 3rd_005 |
| 2023/02/25 | yyy.jp | yyy_002 | 3rd_006 |
| 2023/03/05 | yyy.jp | ||
| 2023/03/15 | yyy.jp | ||
| 2023/03/25 | yyy.jp | ||
| 2023/04/05 | yyy.jp | yyy_003 | 3rd_010 |
| 2023/04/15 | yyy.jp | yyy_003 | 3rd_011 |
| 2023/04/25 | yyy.jp | ||
| 2023/05/05 | yyy.jp | ||
| 2023/05/15 | yyy.jp | ||
| 2023/05/25 | yyy.jp | yyy_004 | 3rd_015 |
| 2023/06/05 | yyy.jp | ||
| 2023/06/15 | yyy.jp | ||
| 2023/06/25 | yyy.jp | yyy_005 | 3rd_018 |
| time | site | td_client_id | td_global_id |
|---|---|---|---|
| 2023/01/05 | zzz.jp | ||
| 2023/01/15 | zzz.jp | zzz_001 | 3rd_002 |
| 2023/01/25 | zzz.jp | ||
| 2023/02/05 | zzz.jp | ||
| 2023/02/15 | zzz.jp | ||
| 2023/02/25 | zzz.jp | zzz_003 | 3rd_006 |
| 2023/03/05 | zzz.jp | zzz_003 | 3rd_007 |
| 2023/03/15 | zzz.jp | zzz_003 | 3rd_008 |
| 2023/03/25 | zzz.jp | ||
| 2023/04/05 | zzz.jp | ||
| 2023/04/15 | zzz.jp | zzz_004 | 3rd_011 |
| 2023/04/25 | zzz.jp | zzz_004 | 3rd_012 |
| 2023/05/05 | zzz.jp | ||
| 2023/05/15 | zzz.jp | ||
| 2023/05/25 | zzz.jp | zzz_005 | 3rd_015 |
| 2023/06/05 | zzz.jp | ||
| 2023/06/15 | zzz.jp | zzz_005 | 3rd_017 |
| 2023/06/25 | zzz.jp | zzz_005 | 3rd_018 |
+call_unification:
http_call>: https://api-cdp.treasuredata.com/unifications/workflow_call
headers:
- authorization: ${secret:td.apikey}
method: POST
retry: true
content_format: json
content:
run_canonical_ids: true
run_enrichments: true
run_master_tables: true
full_refresh: true
keep_debug_tables: true
unification:
!include : unification_ex1.ymlname: test_id_unification_ex1
keys:
- name: td_client_id
invalid_texts: ['']
- name: td_global_id
valid_regexp: "3rd_*"
invalid_texts: ['']
tables:
- database: test_id_unification_ex1
table: site_aaa
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_xxx
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_yyy
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_zzz
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
canonical_ids:
- name: unified_cookie_id
merge_by_keys: [td_client_id, td_global_id]
merge_iterations: 5
master_tables:
- name: master_table_ex1
canonical_id: unified_cookie_id
attributes:
- name: td_client_id
invalid_texts: ['']
array_elements: 5
source_columns:
- {table: site_aaa, order: first, order_by: td_client_id, priority: 1}
- {table: site_xxx, order: first, order_by: td_client_id, priority: 2}
- {table: site_yyy, order: first, order_by: td_client_id, priority: 3}
- {table: site_zzz, order: first, order_by: td_client_id, priority: 4}
- name: td_global_id
valid_regexp: "3rd_*"
invalid_texts: ['']
source_columns:
- {table: site_aaa, order: last, order_by: time, priority: 1}
- {table: site_xxx, order: last, order_by: time, priority: 1}
- {table: site_yyy, order: last, order_by: time, priority: 1}
- {table: site_zzz, order: last, order_by: time, priority: 1}While this algorithm is commonly referred to as the Union-Find Algorithm, it will be referred to as the Unification Algorithm in this document. The Unification Algorithm represents the relationships between keys as a directed graph and transforms the graph into a structure that allows the system to identify groups of keys as representing the same individual through iterative processing.
The +extract_and_merge task in the workflow generates the graph_unify_loop_0 table. This represents the initial state of the graph, illustrating the "follower -> leader" relationships between keys.

The initial graph represented by the graph_unify_loop_0 table is visualized using Graphviz as shown below.

Let’s examine how the graph_unify_loop_0 table, which represents the initial graph, is generated.
canonical_ids:
- name: unified_cookie_id
merge_by_keys: [td_client_id, td_global_id]
merge_iterations: 5In the merge_by_keys: section of canonical_ids:, keys used for stitching are listed in order of priority. This priority influences how the graph is constructed.
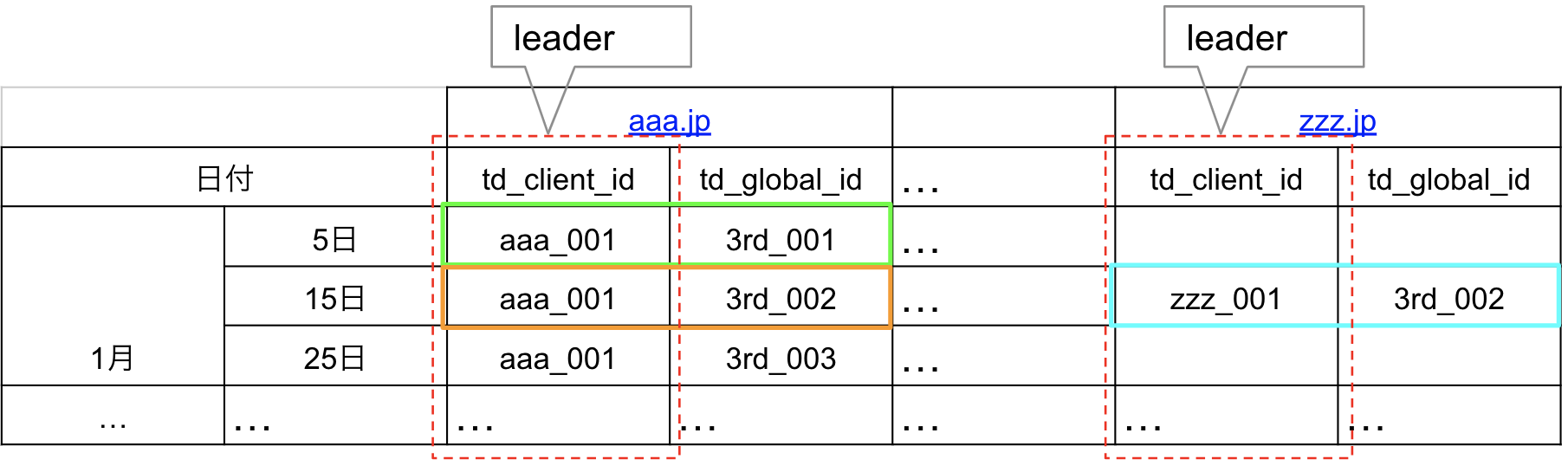
The graph_unify_loop_0 table is generated from the original data through the following steps:

- Among all key columns, the highest-priority key is designated as the leader.
- All key columns (including the leader) are expanded into rows as followers paired with their leader.
- The source table is similarly expanded for all tables.
- The
graph_unify_loop_0table is created by performing aUNION ALLon all tables and extracting unique pairs offollower_id,follower_ns,leader_id, andleader_ns.
The follower_ns and leader_ns specify the key each ID belongs to (in this example, 1 corresponds to td_client_id, and 2 to td_global_id). The priority of keys in this setup is [1, 2].
Using the graph from graph_unify_loop_0, leaders are updated based on the following rules:
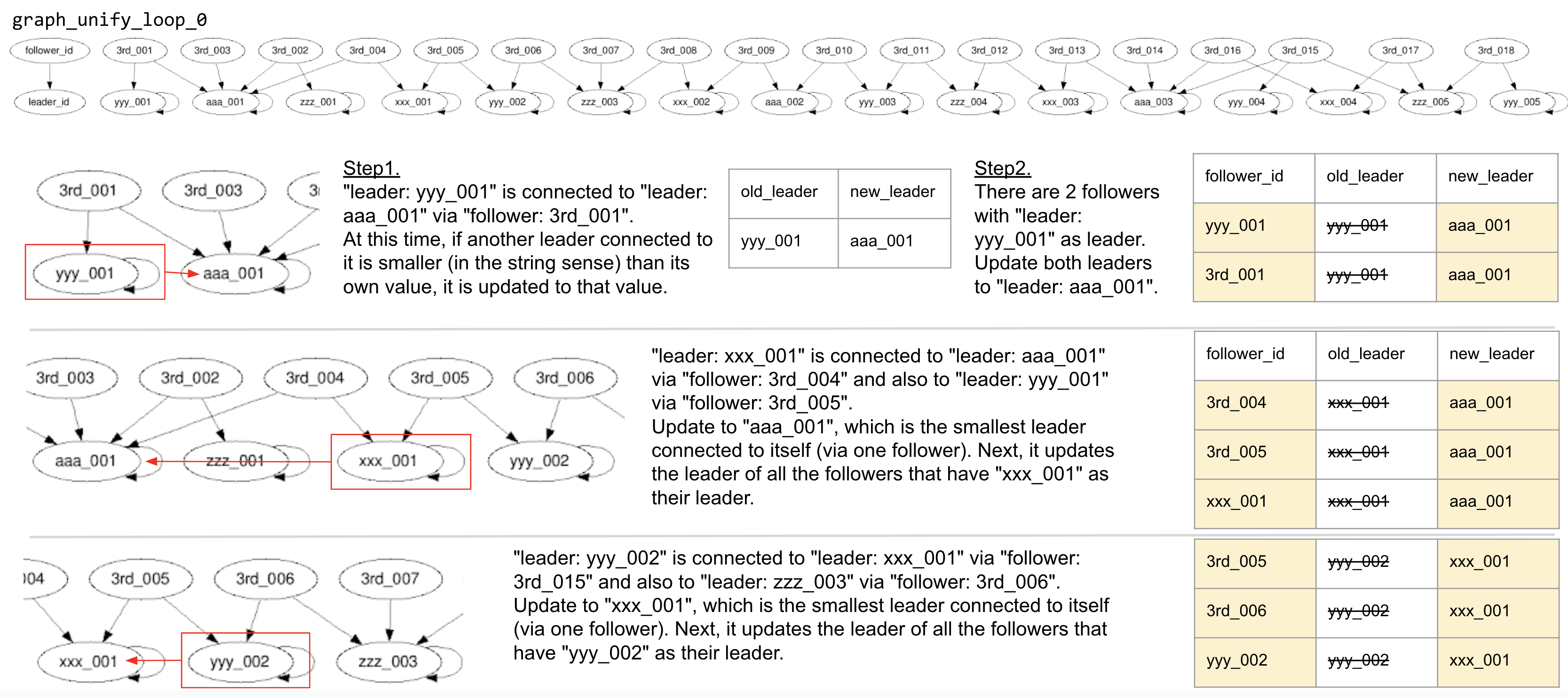
- For each leader, compare its value with all other leaders connected via a single follower.
- If a smaller value exists (in terms of string comparison), the leader is replaced by the one with the smaller value. The original leader becomes the old leader and is replaced by the new leader.
- An "old_leader -> old_leader" relationship will always exist and must be replaced by "old_leader -> new_leader." This change signifies that the old leader is now a follower of the new leader.
The table created after all leaders are updated to their new leaders becomes the graph_unify_loop_1 table.
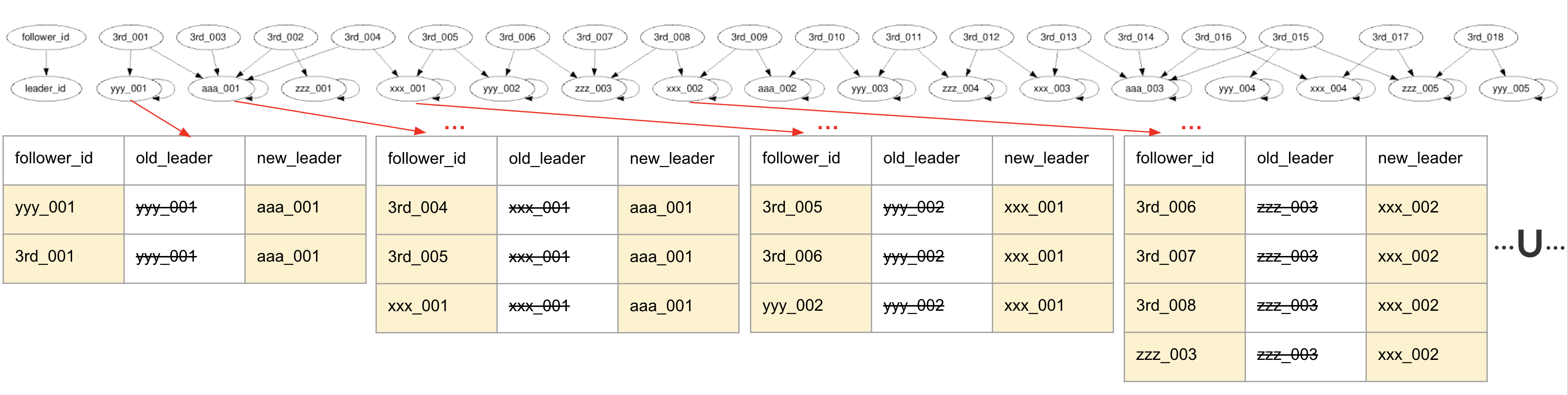
This process results in many leaders being replaced, with old leaders pointing to new leaders as followers. The same process is repeated in subsequent loops.




In this example, with merge_iterations: set to 5, graph_unify_loop_5 represents the final state of the algorithm. Note that this table is output as graph rather than graph_unify_loop_5.
The Unification Algorithm is guaranteed to converge. In graph_unify_loop_4, only one leader remains, and all followers point to it. This is considered a converged state. The convergence conditions are:
- A single leader is consolidated for each individual.
- All keys point exclusively to this leader.
Once converged, a canonical ID can be assigned to all keys for the same individual. In this example, a minimum of 4 iterations (merge_iterations: 4) is necessary to achieve convergence.
Setting a higher value for merge_iterations: is not problematic since processing stops upon convergence. However, note that graph_unify_loop_N tables are only created up to the point of convergence.
If the order in merge_by_keys: is changed to prioritize td_global_id as shown below, the graph evolution will differ completely:
canonical_ids:
- name: unified_cookie_id
# merge_by_keys: [td_client_id, td_global_id]
merge_by_keys: [td_global_id, td_client_id]
merge_iterations: 5




You might think that a good merge_by_keys: order is one that minimises the number of loops, but this is not true. (To begin with, finding the order of keys that minimises the number of loops is not realistic, as you have to run every combination of the order at least once.)
The important thing is not the number of loops, but to set the order so that the canonical_id generated for each individual is as invariant as possible (for subsequent workflow updates).
The process of assigning canonical_id to the final graph after running the Unification Algorithm is executed through the +canonicalize task. For each user, a canonical_id is generated based on the leader's value, and the same ID is distributed to all its followers.
The canonical_id is derived based on the value of the leader key (graph.leader_id) using the following calculation:
to_base64url(
to_big_endian_64(
bitwise_xor(
from_big_endian_64(
substr(
sha256(to_utf8(graph.leader_id)), 1, 8
)
), leader_keys.key_mask_low64i
)
) || leader_keys.key_mask_high8b
)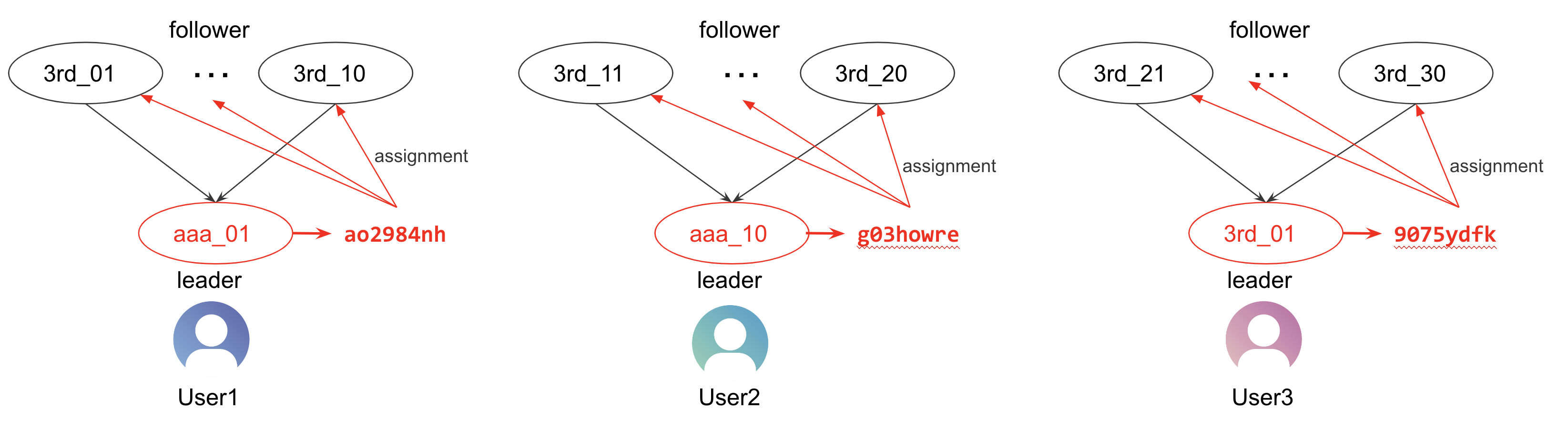
In the above example, canonical_id for User1 and User2 is generated based on the td_client_id that became the leader. In contrast, User3's td_client_id is absent, so the leader is set to the next prioritized value (td_global_id), and the canonical_id is generated accordingly. The generated canonical_id is also assigned to all connecting followers, ensuring that one leader and all its followers share the same canonical_id. The resulting lookup table records this information, allowing you to see the canonical_id assigned to each key.
The canonical_id is not guaranteed to remain consistent (for the same user) across every run of the Unification Workflow.
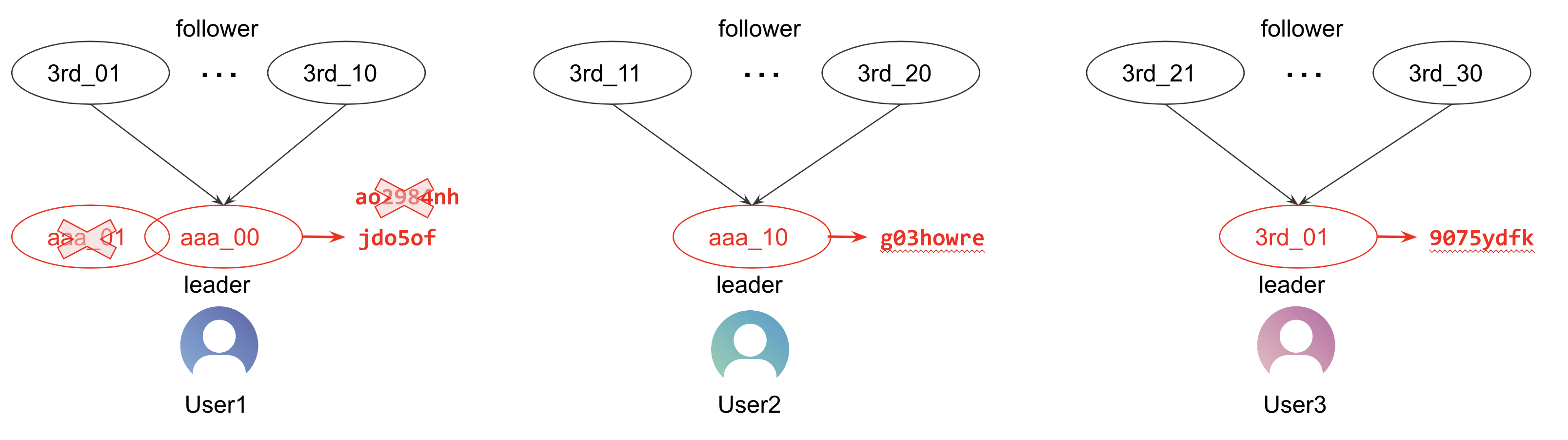
In the next update, suppose a smaller value leader, "aaa_00", appears for User1. In this case, User1's leader becomes "aaa_00" (as the smallest value becomes the sole leader), and a different canonical_id is generated. A different canonical_id implies a different individual, indicating the emergence of a new user. For example, in Audience Studio, which uses this canonical_id, the cdp_customer_id for User1 would change.
It is crucial to ensure that the canonical_id remains as consistent as possible across updates to the Unification Workflow. The order of keys in merge_by_keys: has a significant impact on the immutability of canonical_id.
The Unification Algorithm prioritizes the keys specified in merge_by_keys: in order, setting the earliest (highest priority) key as the leader whenever possible. This means the key at the top of the list is often chosen as the leader for each user.
Therefore, merge_by_keys: should be set with keys ordered from those least likely to change over time to ensure stability. For users who lack the highest-priority key, the second-priority key becomes the leader, making the order of keys critically important.
- Good:
merge_by_keys: [email, td_global_id]emailis less likely to change or increase for individuals, ensuring the same value is selected across updates (and thus a consistentcanonical_id).
- Good:
merge_by_keys: [member_id, email, td_global_id]member_idorcustomer_idis stable for individuals, ensuring the same value is selected across updates (and thus a consistentcanonical_id).
- Bad:
merge_by_keys: [td_client_id, email, td_global_id]td_client_idmay change over time. If a newly generated value is smaller than the previous minimum, it becomes the leader, resulting in a differentcanonical_idfrom the previous run.
Here, we will closely examine the tables outputted in this example. This will provide more detailed insights than the explanation provided in Unification Output, including the meaning of each column in the tables.
A database named cdp_unification_${name}, based on the name: value defined in unification_ex1.yml, is created to store the results. In this example, the database is named cdp_unification_test_id_unification_ex1.
name: test_id_unification_ex1 # Unification Name
keys:
- name: td_client_id
- name: td_global_id
tables:
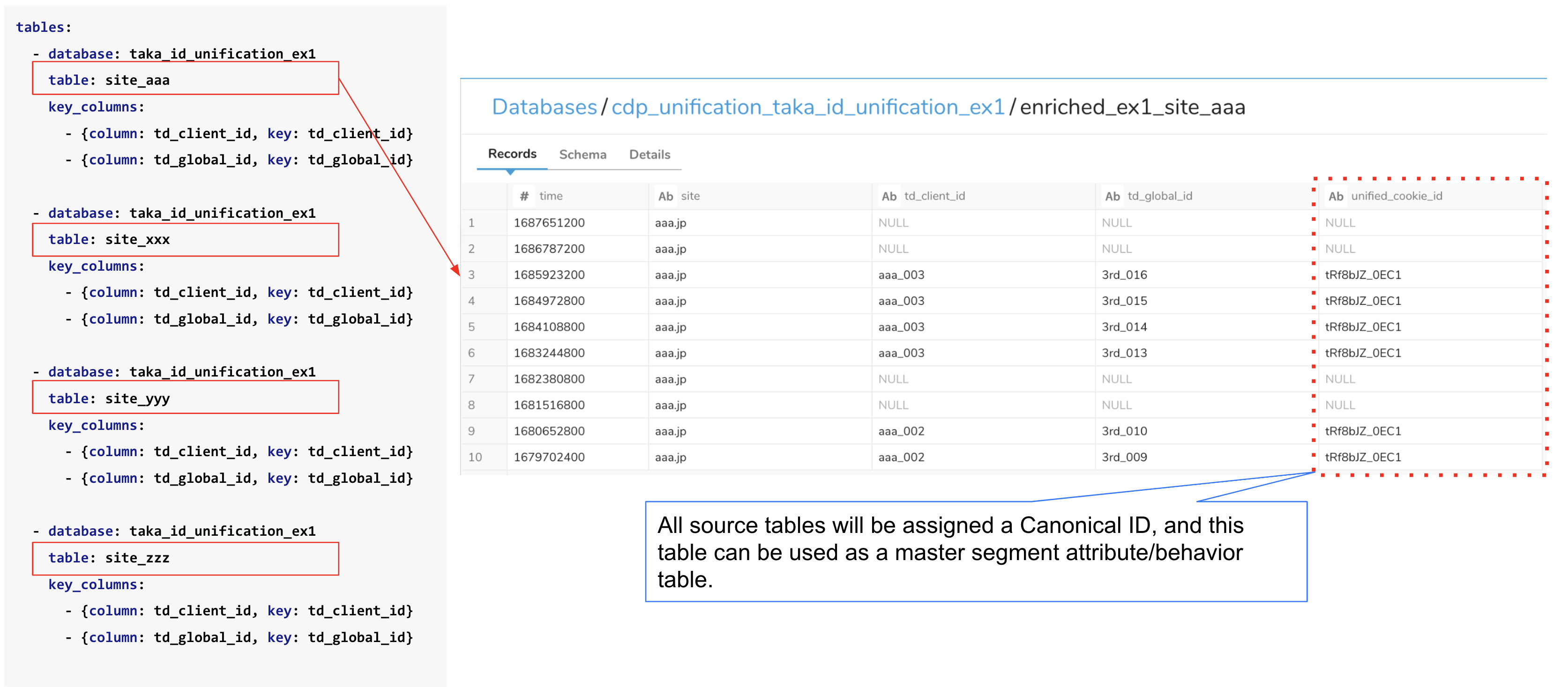
- database: test_id_unification_ex1
table: ex1_site_aaa
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}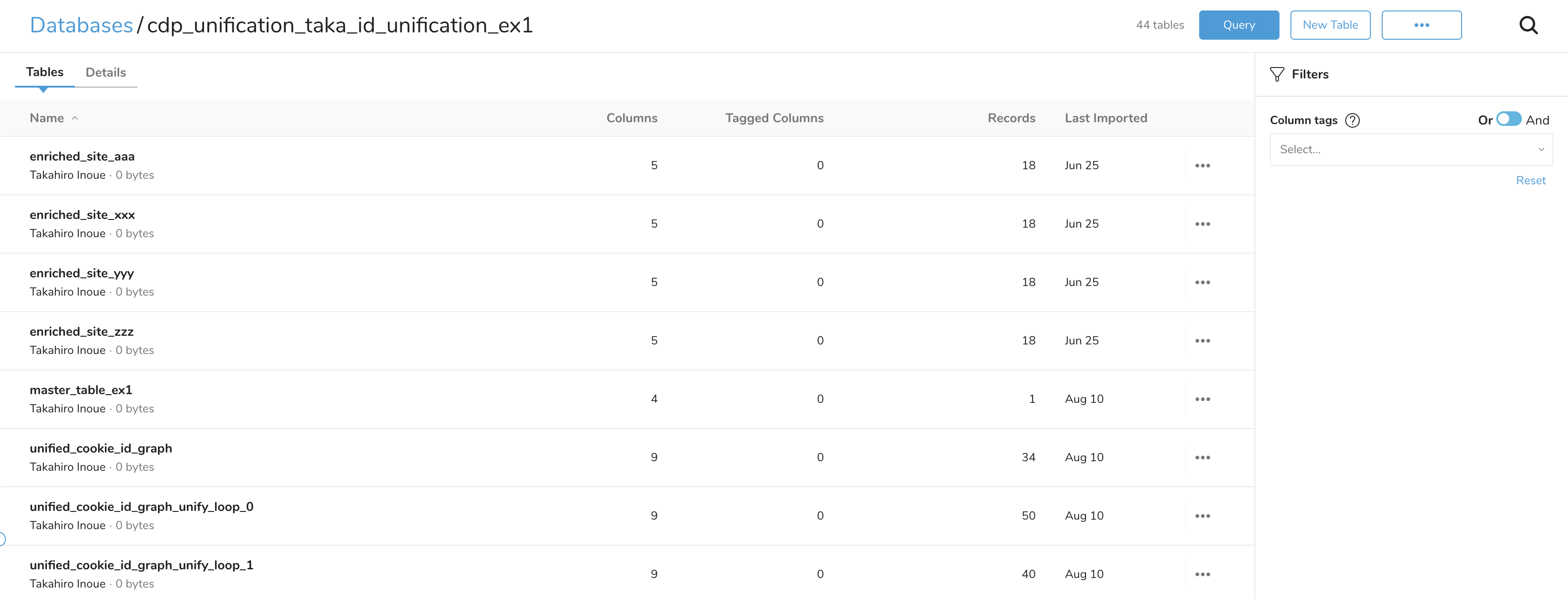
In this example, the table is named master_table_ex1.
master_tables:
- name: master_table_ex1
canonical_id: unified_cookie_id
attributes:
- name: td_client_id
invalid_texts: ['']
array_elements: 5
source_columns:
- {table: site_aaa, order: first, order_by: td_client_id, priority: 1}
- {table: site_xxx, order: first, order_by: td_client_id, priority: 2}
- {table: site_yyy, order: first, order_by: td_client_id, priority: 3}
- {table: site_zzz, order: first, order_by: td_client_id, priority: 4}
- name: td_global_id
valid_regexp: "3rd_*"
invalid_texts: ['']
source_columns:
- {table: site_aaa, order: last, order_by: time, priority: 1}
- {table: site_xxx, order: last, order_by: time, priority: 1}
- {table: site_yyy, order: last, order_by: time, priority: 1}
- {table: site_zzz, order: last, order_by: time, priority: 1}The table specified under name: in master_tables: is output. This is used as the master_table in the Master Segment of the Audience Studio. Below is the result from this example.
| unified_cookie_id | td_client_id | td_global_id | time |
|---|---|---|---|
| tRf8bJZ_0EC1 | ["aaa_001", "aaa_001", "aaa_001", "aaa_001", "aaa_002"] | 3rd_018 | 1691675802 |
A record is generated for each canonical_id. In this case, there is only one record. The time column indicates when the table was created.

Apart from the canonical_id, values specified in attributes: are stored. The td_client_id column, for example, picks up a maximum of five values based on the table order and record sequence defined in source_tables:. However, as shown in this example, duplicate values may occur, so caution is needed.
In this example, the tables are named enriched_site_aaa, enriched_site_xxx, enriched_site_yyy, and enriched_site_zzz.
tables:
- database: test_id_unification_ex1
table: site_aaa
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_xxx
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_yyy
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}
- database: test_id_unification_ex1
table: site_zzz
key_columns:
- {column: td_client_id, key: td_client_id}
- {column: td_global_id, key: td_global_id}Tables named enriched_${source_table_name} are output (four in this example). These are used in the Master Segment as attribute_table or behavior_table.
Below is the enriched_site_aaa table.
| time | site | td_client_id | td_global_id | unified_cookie_id |
|---|---|---|---|---|
| 1672876800 | aaa.jp | aaa_001 | 3rd_001 | tRf8bJZ_0EC1 |
| 1673740800 | aaa.jp | aaa_001 | 3rd_002 | tRf8bJZ_0EC1 |
| 1674604800 | aaa.jp | aaa_001 | 3rd_003 | tRf8bJZ_0EC1 |
| 1675555200 | aaa.jp | aaa_001 | 3rd_004 | tRf8bJZ_0EC1 |
| 1676419200 | aaa.jp | |||
| 1677283200 | aaa.jp | |||
| ... | ... | ... | ... | ... |
This translation preserves the structure and technical accuracy of the original content while ensuring clarity in English. Let me know if you need further adjustments!
In this example, the table is named unified_cookie_id_source_key_stats.
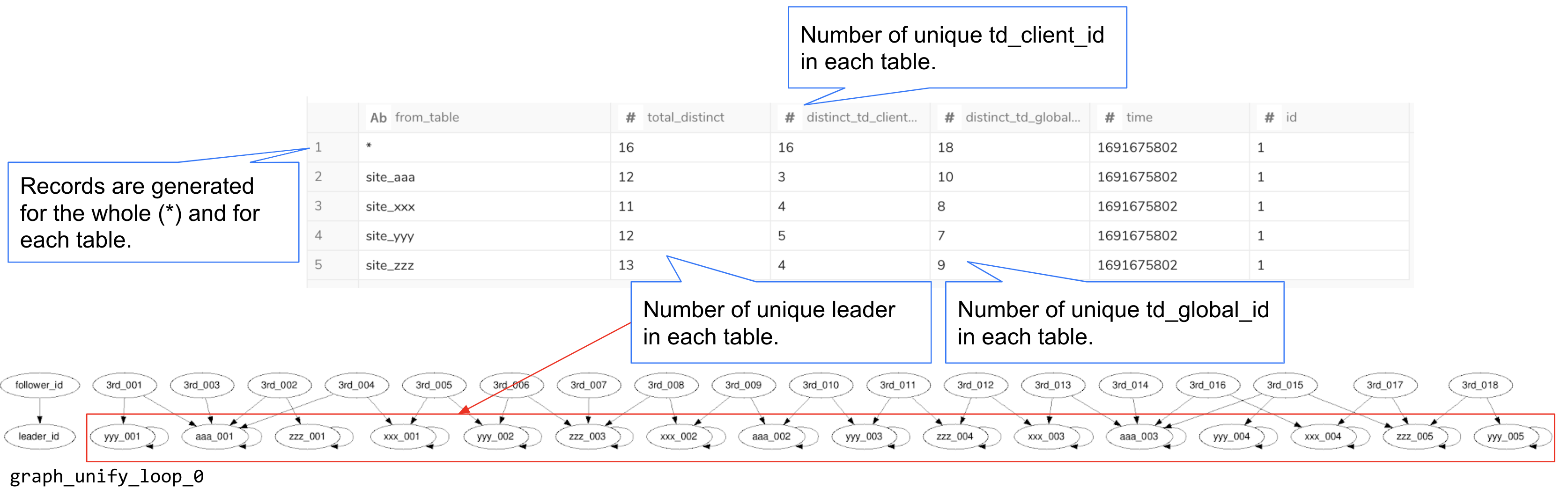
This table outputs statistics from the source table (e.g., the number of unique keys for each column). Only the total_distinct column is calculated from the unified_cookie_id_graph_unify_loop_0 table.
This table appends records with each execution. To retrieve the latest record, execute the following query:
SELECT *
FROM (
SELECT *, RANK() OVER (ORDER BY time DESC) AS id
FROM unified_cookie_id_source_key_stats
)
WHERE id = 1
ORDER BY from_tableThe id column was added by the above SQL query.
| from_table | total_distinct | distinct_td_client_id | distinct_td_global_id | time | id |
|---|---|---|---|---|---|
| * | 16 | 16 | 18 | 1691675802 | 1 |
| site_aaa | 12 | 3 | 10 | 1691675802 | 1 |
| site_xxx | 11 | 4 | 8 | 1691675802 | 1 |
| site_yyy | 12 | 5 | 7 | 1691675802 | 1 |
| site_zzz | 13 | 4 | 9 | 1691675802 | 1 |
In this example, the table is named unified_cookie_id_result_key_stats.
This table records statistics such as the number of canonical IDs (unique individuals) generated for each table after ID unification. The table appends records with each execution. To retrieve the latest record, execute the following query:
SELECT *
FROM (
SELECT *, RANK() OVER (ORDER BY time DESC) AS id
FROM unified_cookie_id_result_key_stats
)
WHERE id = 1
ORDER BY from_tableThe id column was added by the above SQL query.
| from_table | total_distinct | distinct_with_td_client_id | distinct_with_td_global_id | histogram_td_client_id | histogram_td_global_id | time | id |
|---|---|---|---|---|---|---|---|
| * | 1 | 1 | 1 | 16:1 | 18:1 | 1691675802 | 1 |
| site_aaa | 1 | 1 | 1 | 16:1 | 18:1 | 1691675802 | 1 |
| site_xxx | 1 | 1 | 1 | 16:1 | 18:1 | 1691675802 | 1 |
| site_yyy | 1 | 1 | 1 | 16:1 | 18:1 | 1691675802 | 1 |
| site_zzz | 1 | 1 | 1 | 16:1 | 18:1 | 1691675802 | 1 |
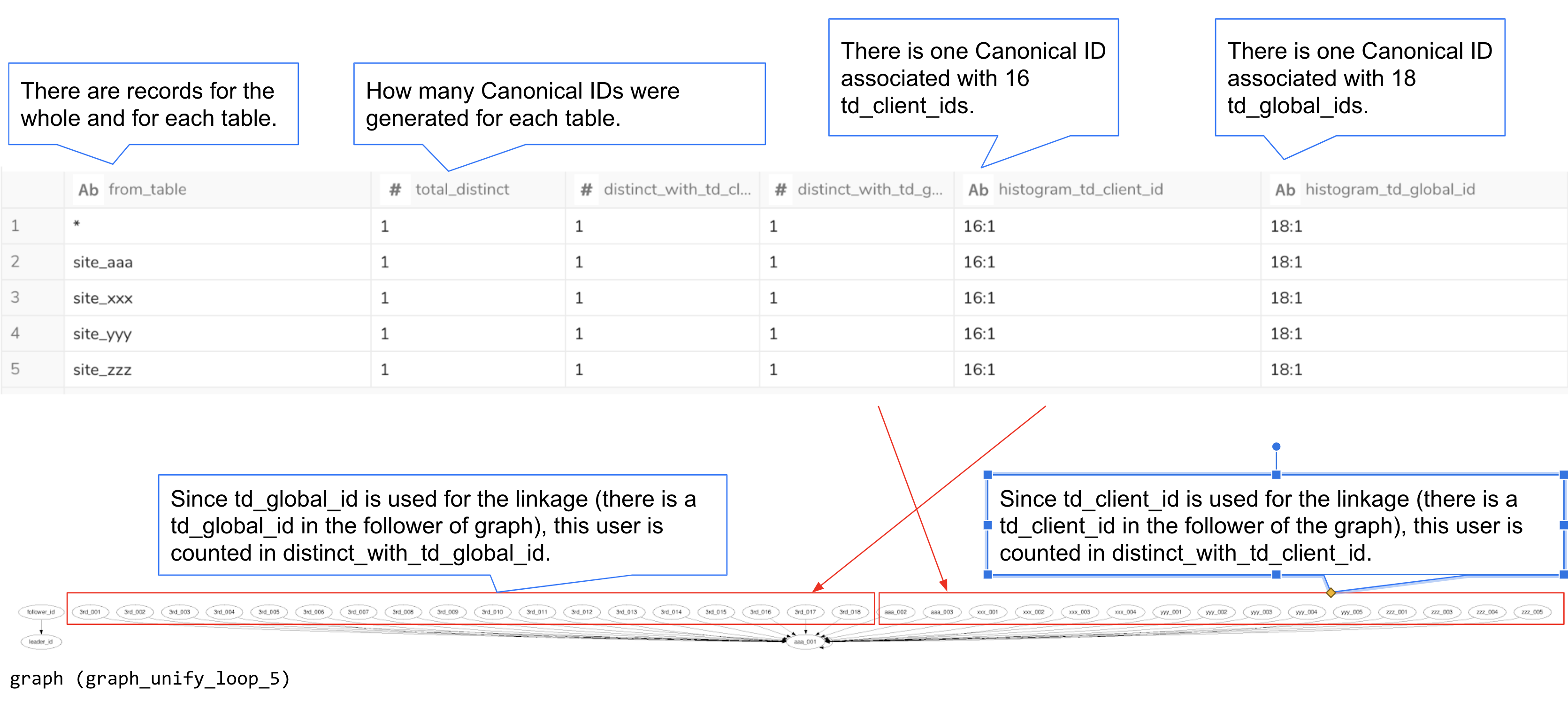
from_table: Indicates the source table for the computed statistics. The"*"row represents all tables combined.total_distinct: Number of unique canonical IDs in the entire table (if"*") or within each specific table.distinct_with_td_client_id: Number of canonical IDs containing at least onetd_client_id. Excludes IDs not stitched withtd_client_id.distinct_with_td_global_id: Number of canonical IDs containing at least onetd_global_id. Excludes IDs not stitched withtd_global_id.histogram_td_client_id: Distribution of how manytd_client_idswere merged into one canonical ID (e.g.,16:1means 16td_client_idsbecame one canonical ID).histogram_td_global_id: Similar tohistogram_td_client_idbut fortd_global_id.
The following group of tables is used internally by the workflow. Some are used for tasks such as convergence judgment.
In this example, the table is named unified_cookie_id_graph_unify_loop_0 (1, 2, 3, 4). This table represents the state of the graph in the Nth loop, frequently referenced in the algorithm's introduction. The last loop is not included here because it has a different name (graph Table).
| follower_id | follower_ns | leader_id | leader_ns | follower_first_seen_at | follower_last_seen_at | follower_source_table_ids | follower_last_processed_at | time |
|---|---|---|---|---|---|---|---|---|
| yyy_002 | 1 | yyy_002 | 1 | 1676419200 | 1677283200 | [7] | 1691675815 | 1691675802 |
| 3rd_015 | 2 | zzz_005 | 1 | 1684972800 | 1684972800 | [8, 5, 7] | 1691675815 | 1691675802 |
| 3rd_015 | 2 | aaa_003 | 1 | 1684972800 | 1684972800 | [8, 5, 7] | 1691675815 | 1691675802 |
| 3rd_015 | 2 | yyy_004 | 1 | 1684972800 | 1684972800 | [8, 5, 7] | 1691675815 | 1691675802 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
follower_id,leader_idColumns: These columns represent the keys for the follower and leader.follower_ns,leader_nsColumns: Indicate the namespace for the follower and leader keys. The order of keys in themerge_by_keys:configuration determines the values 1, 2, etc. In this example,td_client_idis 1, andtd_global_idis 2.follower_first_seen_at,follower_last_seen_atColumns: Record the timestamp when the follower's key value first and last appeared (based on the time column) in the source table.follower_source_table_idsColumns: An array listing the IDs of source tables containing the follower's key values. Use thetablestable (unified_cookie_id_tablesin this example) to determine which source table corresponds to each ID.follower_last_processed_atColumns: The timestamp when the follower was last processed in the loop.
In this example, the table is named unified_cookie_id_graph. It represents the graph's state in the final specified loop.
In this example, the table is named unified_cookie_id_lookup. This table stores all key values in a single row and allows the lookup of a key's canonical_id. It is used to create the master and enriched tables.
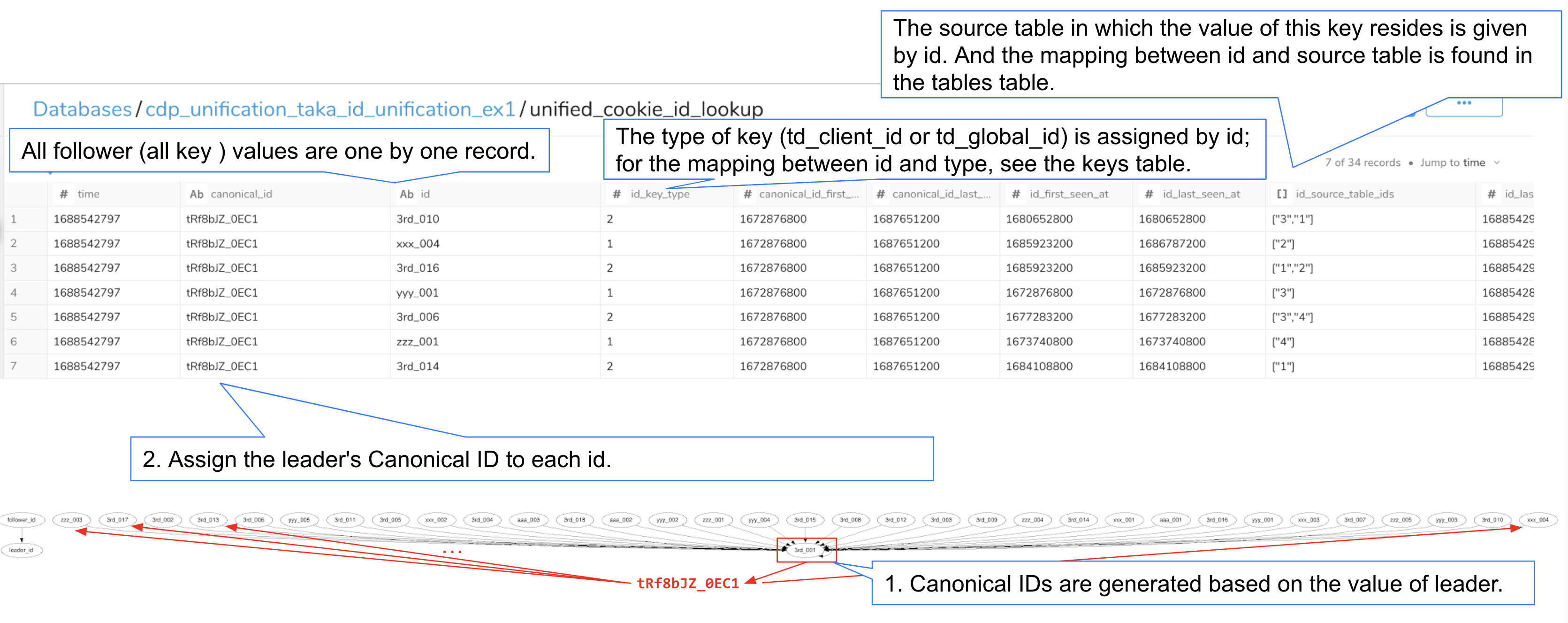
canonical_id | id | id_key_type | canonical_id_first_seen_at | canonical_id_last_seen_at | id_first_seen_at | id_last_seen_at | id_source_table_ids | id_last_processed_at | time |
|---|---|---|---|---|---|---|---|---|---|
| tRf8bJZ_0EC1 | 3rd_016 | 2 | 1672876800 | 1687651200 | 1685923200 | 1685923200 | [5, 6] | 1691675863 | 1691675802 |
| tRf8bJZ_0EC1 | aaa_001 | 1 | 1672876800 | 1687651200 | 1672876800 | 1675555200 | [5] | 1691675815 | 1691675802 |
| tRf8bJZ_0EC1 | yyy_003 | 1 | 1672876800 | 1687651200 | 1680652800 | 1681516800 | [7] | 1691675851 | 1691675802 |
| tRf8bJZ_0EC1 | 3rd_010 | 2 | 1672876800 | 1687651200 | 1680652800 | 1680652800 | [7, 5] | 1691675851 | 1691675802 |
Columns not detailed below share the same meanings as in the unified_cookie_id_graph_unify_loop_0 table.
id_key_typeColumn: Indicates the key type (number) corresponding to theid. For mapping betweenkey_typeandkey_name, refer to thekeystable (unified_cookie_id_keysin this example).id_source_table_idsColumn: Lists the source tables containing theid. Use thetablestable (unified_cookie_id_tablesin this example) to map eachtable_idto atable_name.
This table maps each key to its corresponding id (1, 2, ...). It is used to identify the key_name from the id_key_type column in the lookup table.
| key_type | key_name | time |
|---|---|---|
| 1 | td_client_id | 1691675802 |
| 2 | td_global_id | 1691675802 |
This table maps each source table to an assigned id. It is used to identify the table_name from the id_source_table_ids column in the lookup table.
| table_id | table_name | time |
|---|---|---|
| 5 | site_aaa | 1691675802 |
| 6 | site_xxx | 1691675802 |
| 7 | site_yyy | 1691675802 |
| 8 | site_zzz | 1691675802 |