The do_not_merge_key: option applies stitching rules that differ from the traditional Unification stitching rules:
- If the values of the key specified in
do_not_merge_key:are different, records must not be stitched together (even if other keys link them). - Records without this key's value can be stitched together using other keys.
- You have a unique key (e.g.,
member_id,customer_id) to ensure personal uniqueness. - For records lacking this key, you want to stitch based on secondary keys (e.g.,
email,tel) wherever possible.
By setting do_not_merge_key: member_id, records with distinct member_ids remain separate. For records without member_id, stitching proceeds using the available keys.
Let's deepen our understanding with specific examples.
This page use a single, simple table for this example.
| member_id | tel | name | |
|---|---|---|---|
| 1 | a@ex.com | 1111 | Taka |
| 2 | a@ex.com | 2222 | Tatsuo |
| 3 | b@ex.com | 3333 | Naruse |
| 3 | b@ex.com | 4444 | Yuichiro |
| NULL | c@ex.com | 5555 | Minero |
| NULL | c@ex.com | 6666 | Kaz |
First, let's introduce the Workflow (WF) to be executed in this section.
+call_unification:
http_call>: https://api-cdp.treasuredata.com/unifications/workflow_call
headers:
- authorization: ${secret:td.apikey}
method: POST
retry: true
content_format: json
content:
run_canonical_ids: true
run_enrichments: true
run_master_tables: true
full_refresh: true
keep_debug_tables: true
unification:
!include : unification_ex4.ymlname: test_id_unification_ex4
keys:
- name: member_id
- name: email
tables:
- database: test_id_unification_ex4
table: site_aaa
key_columns:
- {column: member_id, key: member_id}
- {column: email, key: email}
canonical_ids:
- name: person_id
merge_by_keys: [member_id, email]
merge_iterations: 3
do_not_merge_key: member_id
master_tables:
- name: master_table_ex4
canonical_id: person_id
attributes:
- name: member_id
source_columns:
- {table: site_aaa, priority: 1}
- name: email
source_columns:
- {table: site_aaa, priority: 1}
- name: tel
array_elements: 2
source_columns:
- {table: site_aaa, priority: 1}
- name: name
array_elements: 2
source_columns:
- {table: site_aaa, priority: 1}For example, consider scenarios where the email used as a key includes shared addresses like mailing lists or family emails. In such cases, linking data based solely on email might mistakenly associate different individuals.
- However, removing email as a key would hinder proper stitching.
- On the other hand, there may also be keys like
member_idthat ensure personal uniqueness.
Here’s a potential stitching approach you might consider:
- Prioritize stitching based on the values of
member_idwherever possible. - If no
member_idvalue exists, attempt stitching using email as a secondary key.
Let’s revisit the table below.
| member_id | tel | name | |
|---|---|---|---|
| 1 | a@ex.com | 1111 | Taka |
| 2 | a@ex.com | 2222 | Tatsuo |
| 3 | b@ex.com | 3333 | Naruse |
| 3 | b@ex.com | 4444 | Yuichiro |
| NULL | c@ex.com | 5555 | Minero |
| NULL | c@ex.com | 6666 | Kaz |
Given this data:
- Rows 1 and 2 share the same email but different
member_ids, so they shouldn’t be merged. - Rows 3 and 4 share the same
member_idand should be merged. - Rows 5 and 6 lack
member_id, so they should be merged based on email.
This ideal stitching behavior could be achieved using a specific unification option: do_not_merge_key.
Let’s consider a conventional approach without do_not_merge_key by configuring canonical_ids as shown below:
canonical_ids:
- name: person_id
merge_by_keys: [member_id, email]
merge_iterations: 3The output (enriched_site_aaa table) wouldn’t meet expectations. Rows 1 and 2, despite having different member_ids, are treated as the same individual because they share the same email. This happens even though their shared email is merely a mailing list address.
| member_id | tel | name | canonical_id | |
|---|---|---|---|---|
| 1 | a@ex.com | 1111 | Taka | 4ydklKlyPnfa |
| 2 | a@ex.com | 2222 | Tatsuo | 4ydklKlyPnfa |
| 3 | b@ex.com | 3333 | Naruse | xqaWYjT4GR3a |
| 3 | b@ex.com | 4444 | Yuichiro | xqaWYjT4GR3a |
| NULL | c@ex.com | 5555 | Minero | NEKDReELMAx |
| NULL | c@ex.com | 6666 | Kaz | NEKDReELMAx |
How can we ensure rows 1 and 2 are treated as different individuals?
Next, let’s configure canonical_ids with the do_not_merge_key option and execute the unification:
canonical_ids:
- name: person_id
merge_by_keys: [member_id, email]
merge_iterations: 3
do_not_merge_key: member_idThis results in the desired output where rows 1 and 2 are treated separately, while rows 5 and 6 are merged based on email.
| member_id | tel | name | canonical_id | |
|---|---|---|---|---|
| 1 | a@ex.com | 1111 | Taka | 4ydklKlyPnfa |
| 2 | a@ex.com | 2222 | Tatsuo | XNKI3XAY1Hja |
| 3 | b@ex.com | 3333 | Naruse | xqaWYjT4GR3a |
| 3 | b@ex.com | 4444 | Yuichiro | xqaWYjT4GR3a |
| NULL | c@ex.com | 5555 | Minero | NEKDReELMAx |
| NULL | c@ex.com | 6666 | Kaz | NEKDReELMAx |
The master_table output is as follows:
| person_id | member_id | tel | name | |
|---|---|---|---|---|
| 58MMqWNFdAhu | 1 | a@ex.com | [1111] | ["Taka"] |
| WDbg4Lovngdu | 2 | a@ex.com | [2222] | ["Tatsuo"] |
| wkL-X_7PU2Ju | 3 | b@ex.com | [4444, 3333] | ["Yuichiro", "Naruse"] |
| UVs_qHcWwZnz | NULL | c@ex.com | [6666, 5555] | ["Kaz", "Minero"] |
The Unification Algorithm for this case is explained.
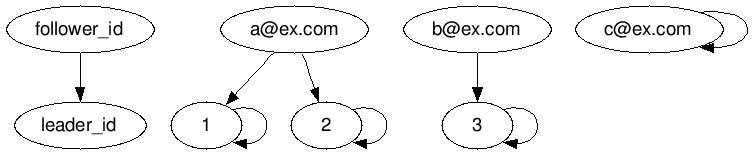
In fact, the initial graph is the final state this time. In the conventional Algorithm, "leader_id: 2" should be replaced (merged) by "leader_id: 1" , but do_not_merge_key: is set to member_id, so that it is not merged. So, no further changes are made.
In this case, four different canonical_ids will be generated.
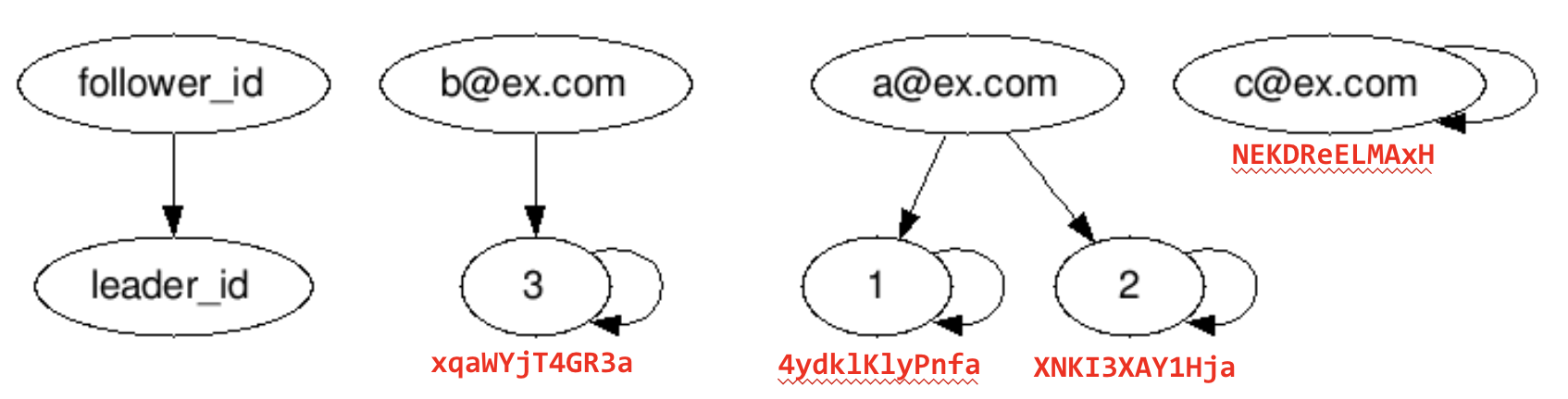
The difference is that "follower: a@ex.com" points to two leaders, "member_id: 1" and "member_id: 2," regardless of the state of convergence.
In fact, there are 2 rows of records for a@ex.com in the lookup table.
| id | canonical_id |
|---|---|
| 1 | 4ydklKlyPnfa |
| 2 | XNKI3XAY1Hja |
| 3 | xqaWYjT4GR3a |
| a@ex.com | 4ydklKlyPnfa |
| a@ex.com | XNKI3XAY1Hja |
| b@ex.com | xqaWYjT4GR3a |
| c@ex.com | NEKDReELMAxH |
This means that the algorithm has converged without "all the followers point to only one leader," which is one of the methods to determine algorithm convergence. However, the other method, "checking the output of the +report_diff task in WF Logs" is still valid.
Finally, let's review the cases in which do_not_merge_key should be used. 1.
- (Assumption) You have one key whose uniqueness is guaranteed (e.g. member_id, customer_id, etc.).
- for records that do not have the value of key 1., we want to proceed with stitching as much as possible, using a key whose uniqueness is not partially guaranteed (e.g., email, tel, etc.).
In this case, if you set do_not_merge_key: member_id, the records will be judged as different persons even if other keys are stitched with the same value, as long as member_id is different. However, for records that do not have member_id, other keys are stitched together to the maximum extent possible.