This misunderstanding often arises from data containing Japanese values. When viewed through the lens of "data deduplication," it is easy to assume that ID Unification automatically standardizes and consolidates identifiers like phone numbers and addresses with variations. However, it’s important to understand the following aspects of ID Unification:
- The ID Unification tool stitches identifiers based on exact matches and does not pre-correct variations in identifier formats.
- If you wish to use identifiers with format variations (e.g., phone numbers, addresses, or names) as stitching keys between tables, you need to standardize these formats beforehand using other methods.
Identifiers used as stitching keys must be unique to each individual.
- Name
- Individuals with the same name may be mistakenly consolidated as the same person.
- IP Address
- Since IP addresses can be reused, multiple individuals may be conflated into one.
- Shared email addresses or mailing lists
- Home phone numbers
td_client_id,td_global_id,td_ssc_idmember_id,customer_id- IDs uniquely generated by the system.
- Mobile phone numbers (associated with individuals)
Be aware that ID Unification does not treat similar key values as the same or infer stitching based on behavioral patterns.
A canonical_id once assigned can change due to updates.
- When updating the unification workflow, if a smaller value than the previous graph's final leader appears, the leader will be replaced, causing the
canonical_idto change. - To minimize changes to the
canonical_id, set immutable keys for individuals at the top of themerge_by_keys:list.
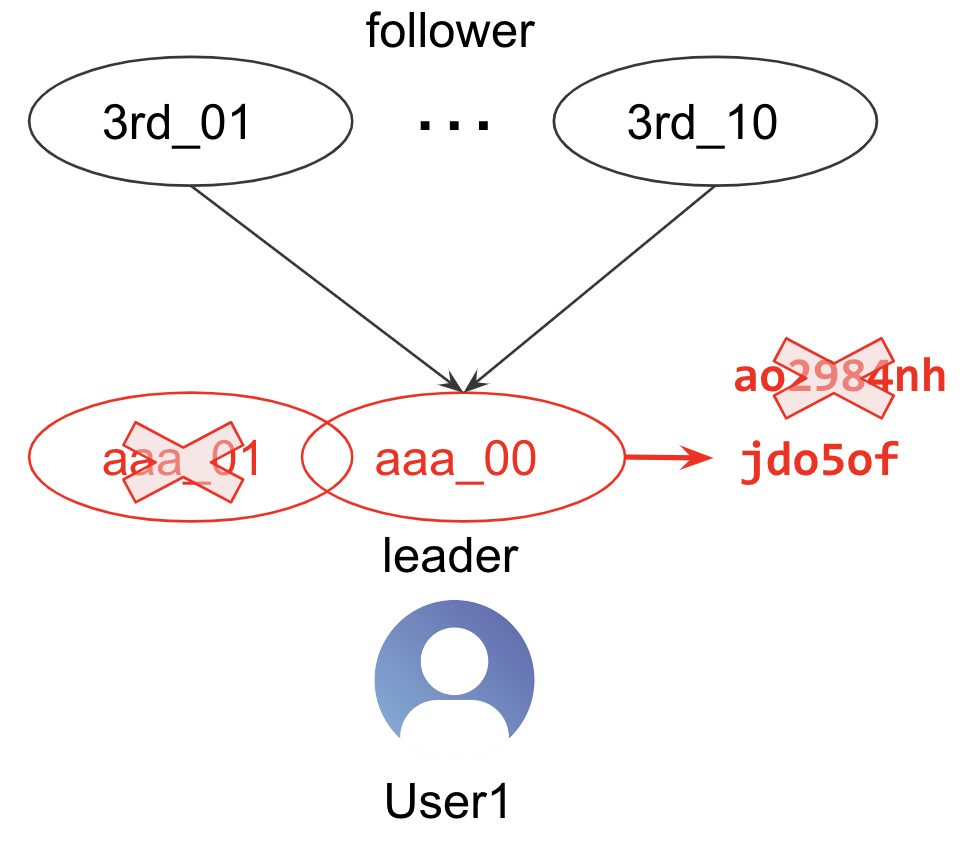
In the example, User1’s canonical_id changes from aaa_01 to aaa_00 because a smaller td_client_id (aaa_00) is introduced. This change means User1’s cdp_customer_id also changes in Audience Studio.
You'll need to consider using persistent_id option.
If placeholder or error values like empty strings or "N/A" are present in the data, all individuals with those values may get linked. However, NULL values are automatically excluded.
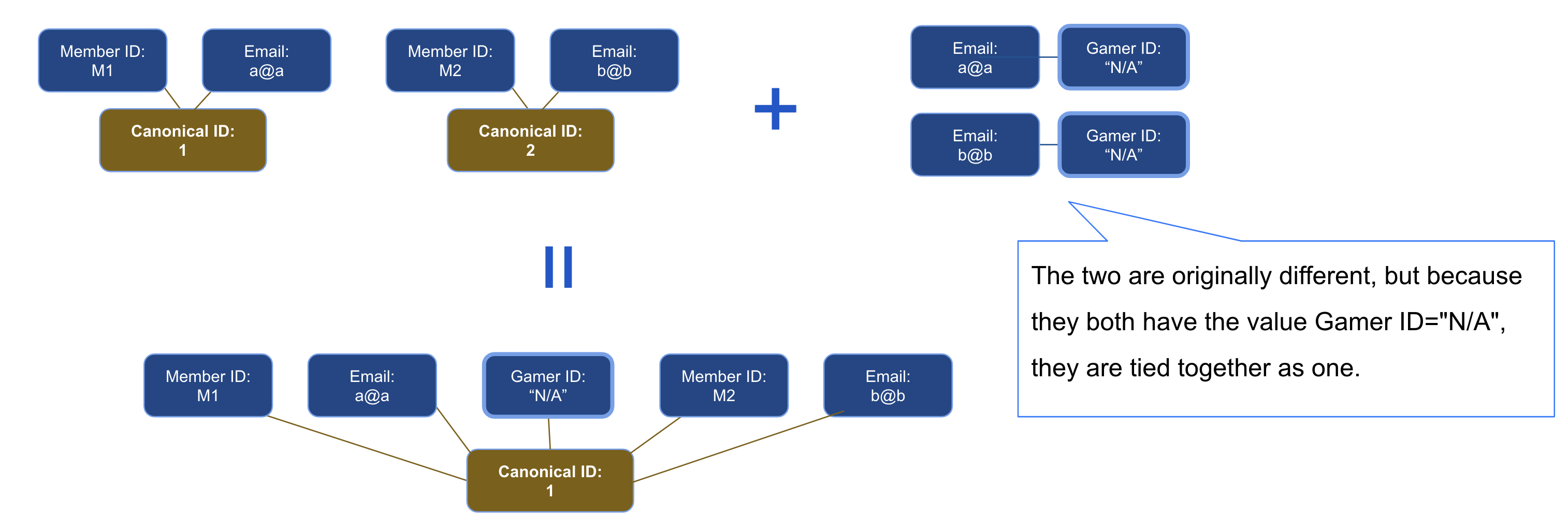
Configure the keys: section in the workflow with the following two control methods for key values. Let’s use an example to explain:
keys:
- name: td_client_id
valid_regexp: "[0-9a-fA-F]{8}-..."
invalid_texts: ['']
- name: td_global_id
valid_regexp: "[0-9a-fA-F]{8}-..."
invalid_texts: ['', '0000000000-...']
- name: email
valid_regexp: ".*@.*"Only values matching the specified regular expression will be used. For example, for td_client_id, only values matching the following regex will be considered:
valid_regexp: "[0-9a-fA-F]{8}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{4}-[0-9a-fA-F]{12}"Values matching specified strings such as:
"", "N/A", "None", "error"can be excluded to prevent unintended linking. Note that NULL is excluded by default.
If the number of iterations in the unification algorithm is insufficient, the stitching process may remain incomplete (i.e., the algorithm has not converged).
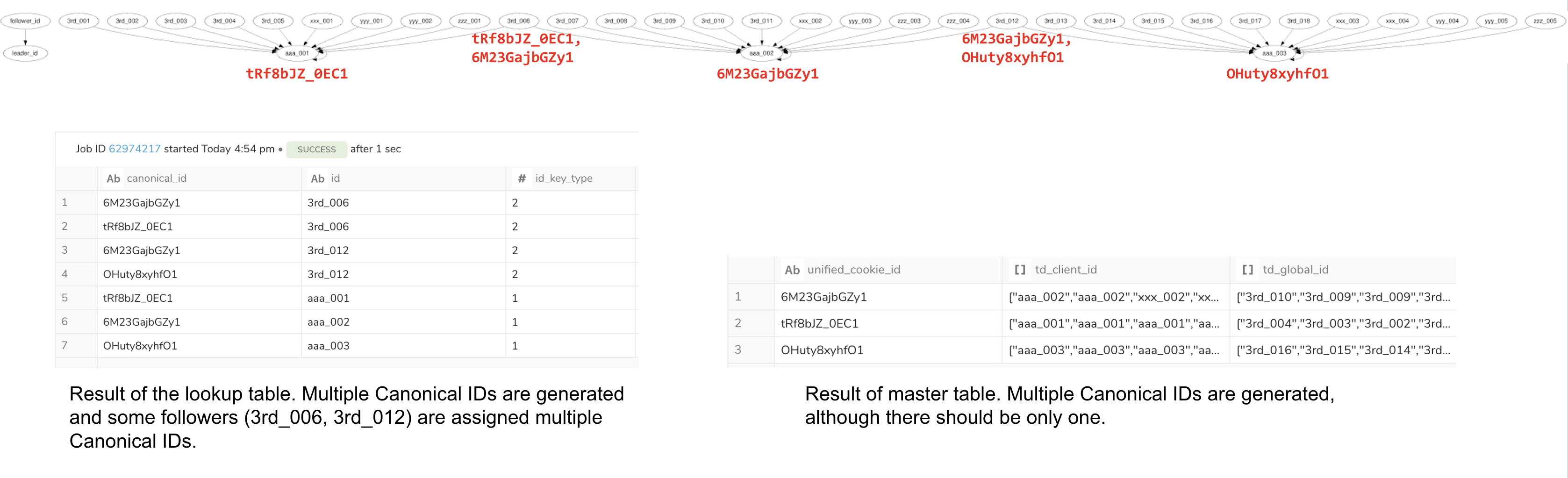
Run the following queries on the graph or lookup table to check if the count is zero. A zero count indicates convergence because a fully converged graph has each key (follower) pointing to a single leader, resulting in only one edge per key.
SELECT id, id_key_type, COUNT(1) AS cnt
FROM ${canonical_id_name}_lookup
GROUP BY 1,2
HAVING 1 < COUNT(1)
ORDER BY cnt DESC| id | id_key_type | cnt |
|---|---|---|
| 3rd_006 | 2 | 2 |
| 3rd_012 | 2 | 2 |
In this example, the query result is 2 rows, indicating the loop is incomplete.
SELECT follower_id, follower_ns, COUNT(1) AS cnt
FROM ${canonical_id_name}_graph
GROUP BY 1,2
HAVING 1 < COUNT(1)
ORDER BY cnt DESC| follower_id | follower_ns | cnt |
|---|---|---|
| 3rd_006 | 2 | 2 |
| 3rd_012 | 2 | 2 |
Similarly, a result of 2 rows shows the loop has not yet converged.
If you are using do_not_merge_key, even in a converged state, followers may point to multiple leaders, so the above queries will not return zero results.
Examine the workflow logs for the report_diff section. If you find a loop iteration where Updated number of records: 0, the algorithm has converged.
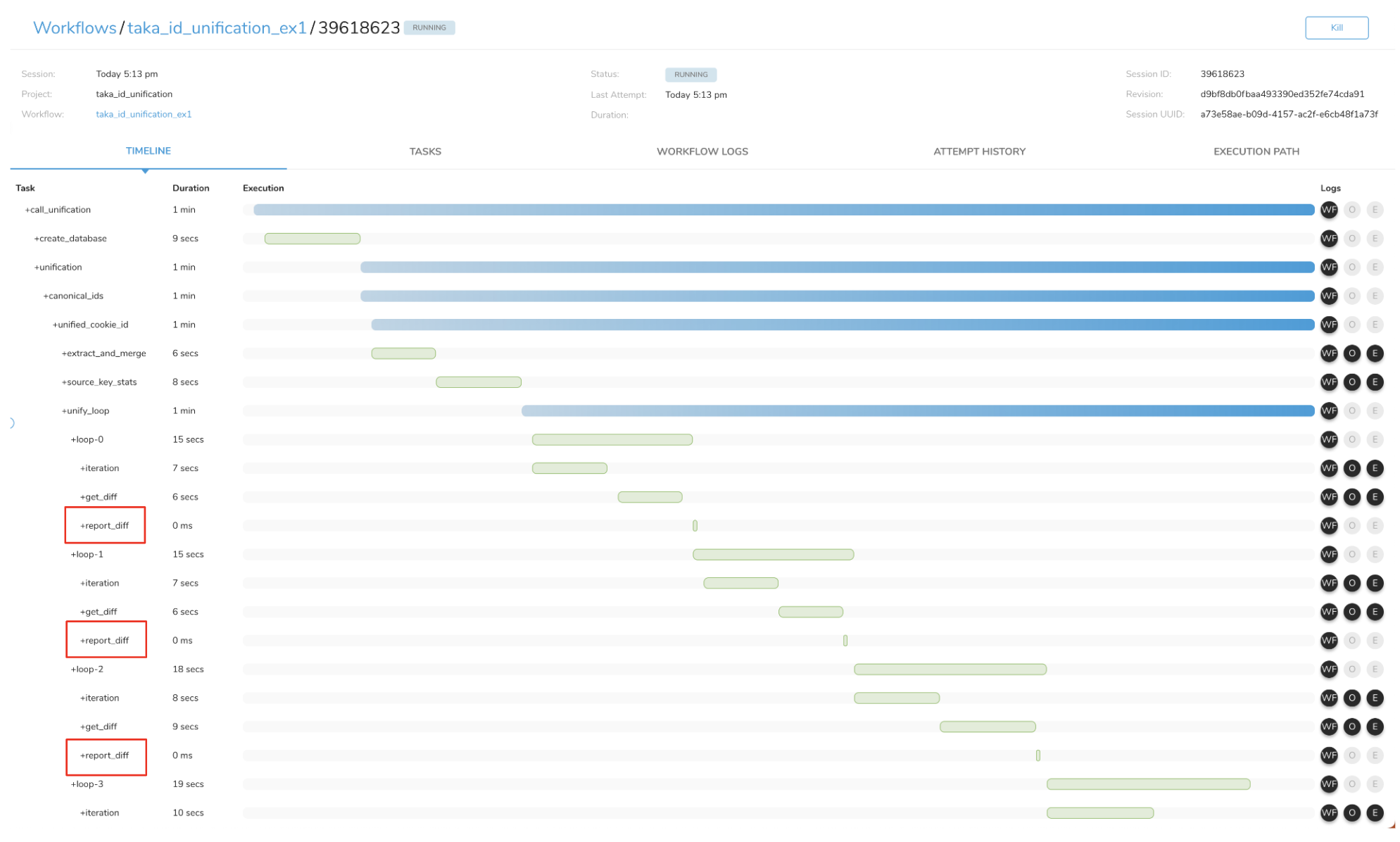
For example:
2023-08-12 00:07:54.070 Updated number of records: 22Here, 22 records were updated in the first loop, indicating no convergence.
2023-08-12 00:09:36.109 Updated number of records: 0By the fourth loop, the count drops to 0, confirming convergence.