A deep dive into how we improved our Hive table scans by 20-30% by making things highly parallelized with PlazmaDB!
Treasure Data's CDP platform provides the capability to analyze customer data coming from various data sources. Internally, we use Apache Hive and Presto to develop our customer data platform.
A major challenge for a platform at the scale of TD is performance. Some data sources, such as web access logs, require query engines to scan, join, and write a massive amount of records. In this article, we will describe how we optimize the scanning part by leveraging our I/O library.
Our implementation of Hive and Presto send a large amount of Amazon S3 GET requests. The number can sometimes reach 10 million per minute. This may sound like a lot, but let me explain, there is a very valid reason why we scan so many S3 objects.
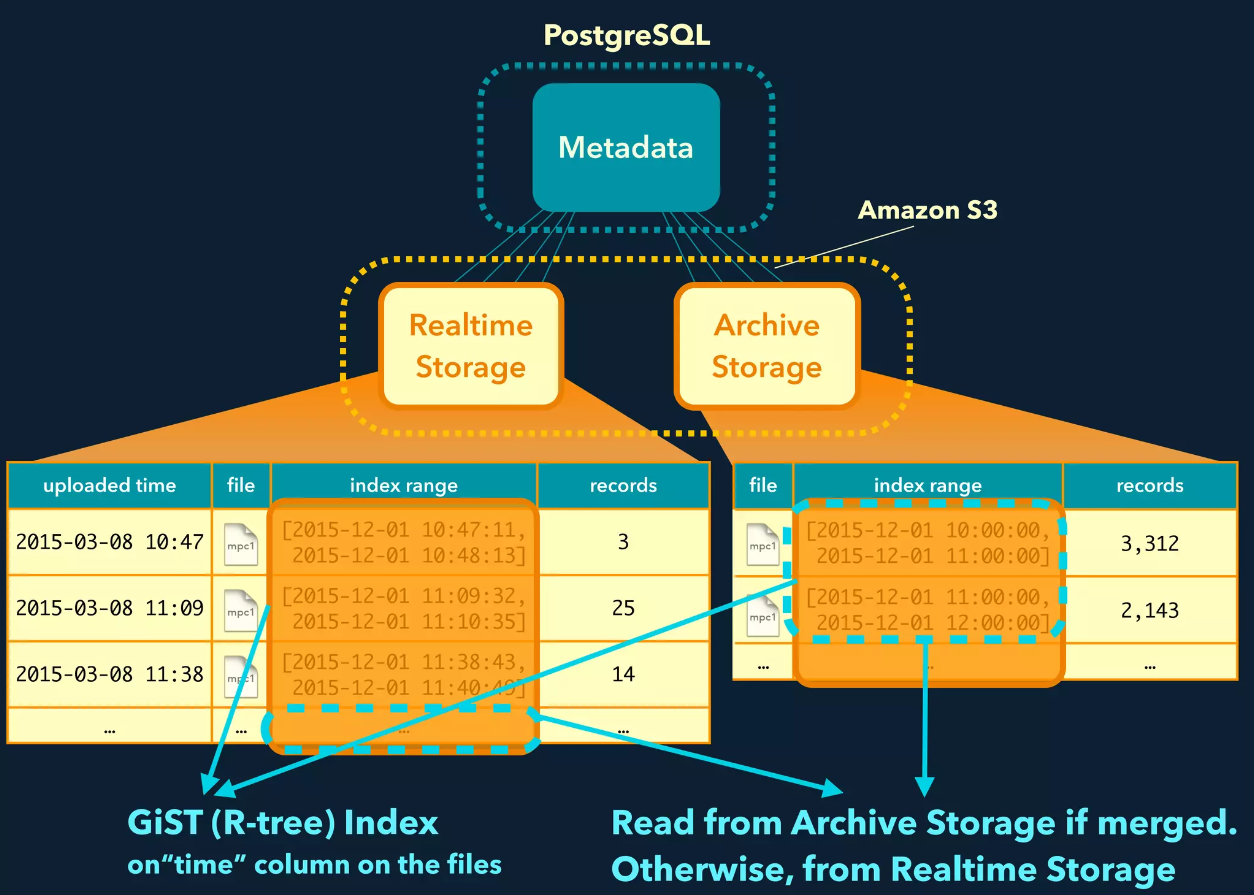
We store records in our tailored storage called Plazma. Plazma is composed of two types of storage, Realtime Storage and Archive Storage. Typically, customers continuously send us records through a log collector such as Fluentd, and Treasure Data Import API ingests the records into Realtime Storage. In order to avoid fragmentation, Plazma periodically merges small S3 objects in Realtime Storage based on partition keys, and then moves the merged ones to Archive Storage. Customers don’t have to care about how or where records are stored because we transparently perform compactions and partitioning. In some scenarios, Hive and Presto have to scan many S3 objects. For example, they may have to read a large number of pre-merged S3 objects in Realtime Storage. In another case, full-scan queries might have to access a wide range of partitioned S3 objects.
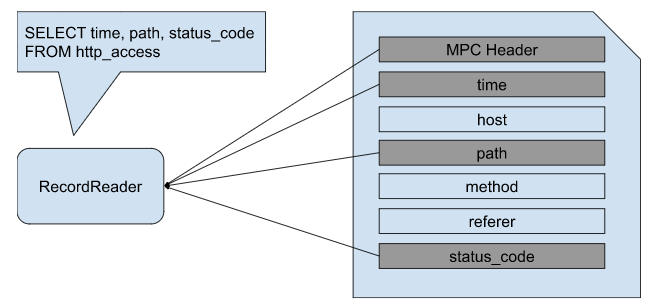
Modern big data systems typically store files using a columnar storage format. Parquet or ORC are well-known examples. Treasure Data developed our columnar storage format, MPC1, designed for schema on read. Simply speaking, MPC1 has N + 1 blocks in each file, one header block and N column blocks.
Our Hive or Presto implementation can send multiple GET requests per file based on projections and file size so as to reduce network I/O. For example, when they scan only 3 of 100 columns, they may make multiple requests to fetch them instead of downloading all 100 columns with 1 request. This can contribute to low latency but the number of HTTP requests can increase.
Now, lets discuss a previous implementation of our RecordReader for Plazma, and how we improved on it in our new implementation. We don't have strict control on what sorts of or how many S3 objects are created. It relies on how customers use Treasure Data CDP. Customers might ingest records very frequently, or they might have to create a table with thousands of columns. That's why we develop our own RecordReader which covers various cases.
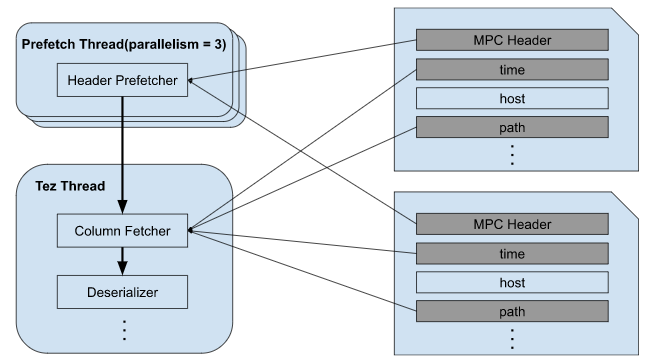
We implemented the first version of RecordReader many years ago. It follows the steps below.
- RecordReader dispatches the list of S3 objects to be scanned to Prefetch Threads
- Header Prefetcher reads MPC headers from the S3 objects on 3 threads
- RecordReader downloads column blocks on a single thread once its header gets ready to read
- RecordReader de-serializes the column blocks
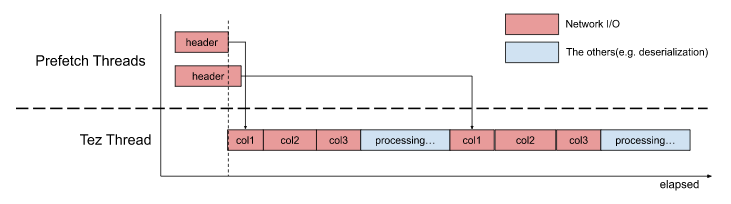
This architecture had slightly reduced latency of Map tasks with fairly simple implementation. But we knew typical table scans still spent 20~30% waiting for column blocks. In actual cases, a single Map task can touch much more S3 objects or read more columns than the above image, and S3 access could block the primary thread of Tez. Theoretically, the 20~30% can be almost zero.
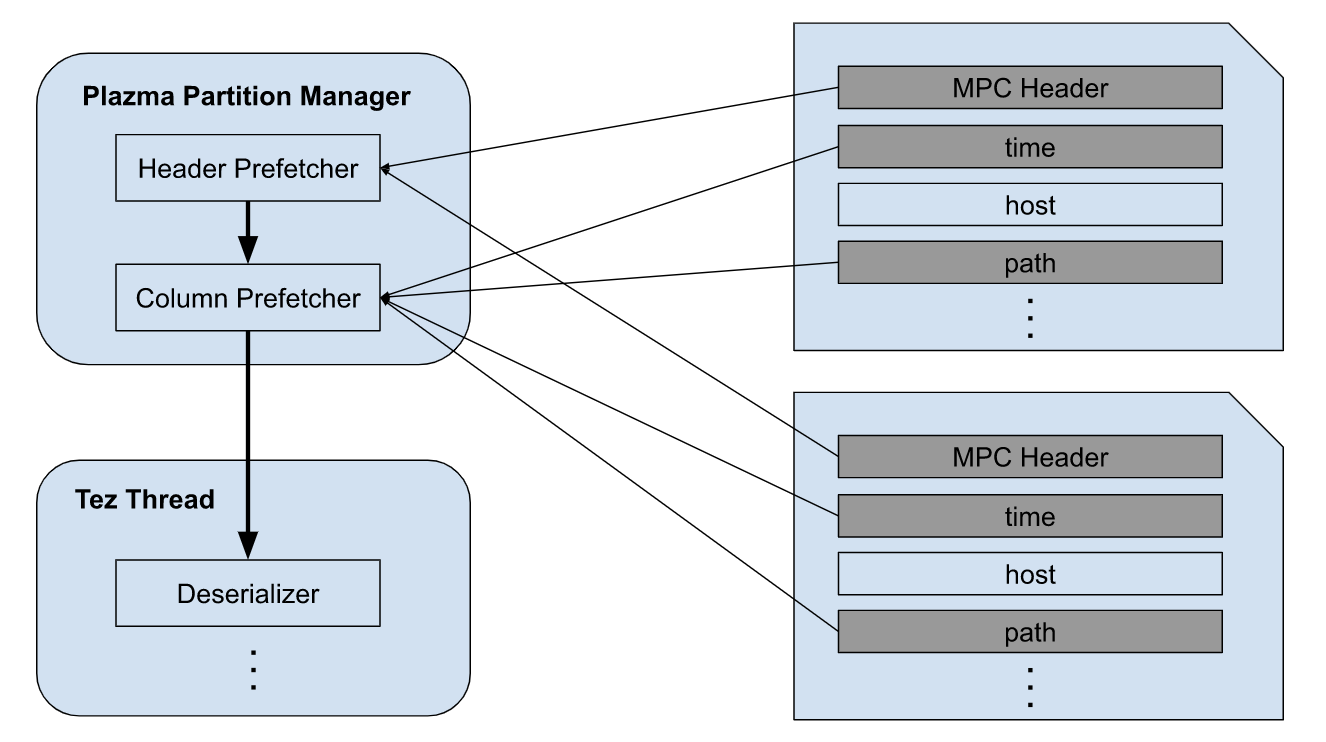
We develop an internal library named as Plazma Partition Manager to abstract access to MPC1 files on S3. It includes a feature to process parallelized S3 I/Os using I/O multiplexing. We originally developed it for Presto, and recently it replaced the Hive I/O layer. The new implementation works as below.
- RecordReader dispatches the list of S3 objects to be scanned to Plazma Partition Manager
- Header Prefetcher reads MPC headers from the S3 objects in parallel
- Column Prefetcher reads column blocks in parallel once its header gets ready
- RecordReader deserializes the column blocks once columns are ready
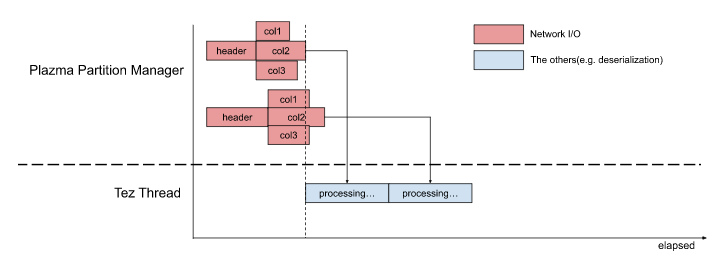
Now, the pre-fetching part is fully optimized as Plazma Partition Manager hides most S3 latency by highly parallelizing S3 GET requests. So, Hive on Tez containers can make use of assigned CPUs more efficiently.
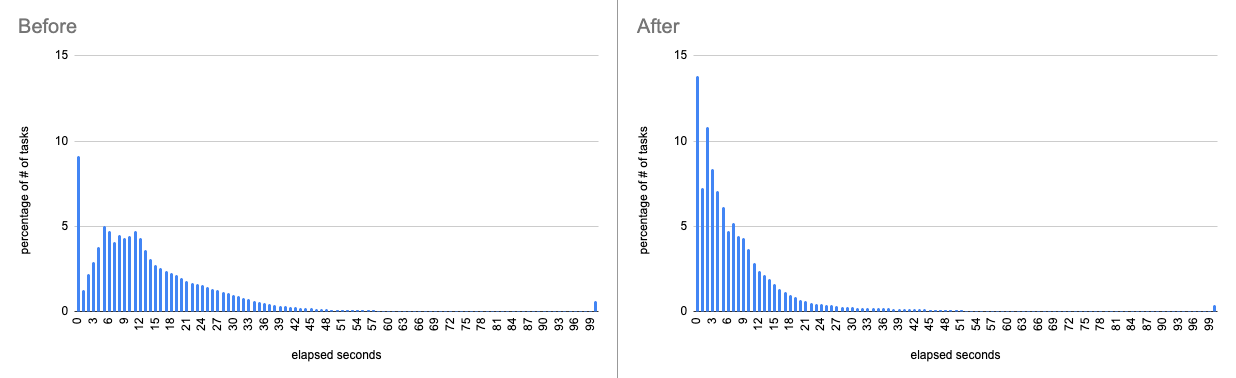
So what is the net impact of these architecture changes? We observed Map tasks of Hive on Tez became much faster, especially when they access a large number of S3 objects or columns. The latency distribution apparently improved after the rollout. We know some Map tasks became 10x faster and those of typical CDP queries became 20~30% faster on average as announced in our monthly release notes.
Hive and Presto currently share the same library to access S3 objects. We expect we can take various advantages by improving Plazma Partition Manager.
We collect metrics in several ways and view them based on a purpose.
- Storage & request Metrics of Amazon S3
- Table scan metrics per query of Hive
- Table scan metrics per split of Presto
We expect we can add detailed and useful app-level metrics in a standard manner.
In this blog post, we covered simple cases but the reality is more complex. For example, we fetch the entire S3 object when it is small enough to avoid the overhead of fetching the initial byte of an S3 object. We theorize that further improvements can be made by having more adaptive algorithms to optimize S3 requests and to reduce S3 cost in Plazma Partition Manager.